Selvaraj and Min: AI-assisted Monitoring of Human-centered Assembly: A Comprehensive Review
Abstract
Detection and localization of activities in a human-centric manufacturing assembly operation will help improve manufacturing process optimization. Through the human-in-loop approach, the step time and cycle time of the manufacturing assemblies can be continuously monitored thereby identifying bottlenecks and updating lead times instantaneously. Autonomous and continuous monitoring can also enable the detection of any anomalies in the assembly operation as they occur. Several studies have been conducted that aim to detect and localize human actions, but they mostly exist in the domain of healthcare, video understanding, etc. The work on detection and localization of actions in a manufacturing assembly operation is limited. Hence, in this work, we aim to review the process of human action detection and localization in the context of manufacturing assemblies. We aim to provide a holistic review that covers the current state-of-the-art approaches in human activity detection across different problem domains and explore the prospective of applying them to manufacturing assemblies. Additionally, we also aim to provide a complete review of the current state of research in human-centric assembly operation monitoring and explore prospective future research directions.
Keywords: Smart manufacturing ┬Ę Industry 4.0 ┬Ę Assembly monitoring ┬Ę AI-assisted manufacturing
Abbreviations
Normalized Mean Absolute Error
Long-term Recurrent Convolutional Network
Convolutional Neural Network
1 Introduction
The advancement in deep learning and machine learning complemented by high-performance computing has propelled industries into the fourth industrial revolution. In the era of Industry 4.0, Cyber-Physical Systems (CPS) play a key role in enabling better visualization of the manufacturing process [ 1ŌĆō 4]. Gao et al. [ 5] discussed the application of data in a smart factory. With the advancement in computer vision, sensor technologies, sensor communication, and Industrial Wireless Sensor Networks (IWSNs), it has become easier to deploy and manage sensors on a large scale to enable connected factories. In a typical manufacturing facility, each product passes through a series of assembly stations consisting of predefined steps called Standard Operating Procedures (SOPs). The productivity of a manufacturing facility is greatly impacted by the quality of the manufacturing assemblies. The manufacturing assembly operations also control the end-product quality. Human-centric smart manufacturing (HSM) has been growing in the recent decade. The HSM involves the integration of human-in-loop with technologies [ 6]. The paradigm of humans in the industry can be seen in Fig. 1. With human-in-loop, the integration of AI technologies and human operators has never been closer. Potentially, AI can assist humans by enabling them to perform day-to-day tasks effectively and effortlessly.
1.1 Scope of the Paper
In this paper, we aim to review the work that has been carried out in the domain of human-centric assembly operation monitoring. The field of monitoring humans and detecting their activity is vast and has been thoroughly reviewed several times in the past. In our work, we focus only on the monitoring of human actions in a manufacturing industrial setting. In addition to reviewing papers that aim to develop methodologies for monitoring human-centric assembly operations, this work also reviews some of the current states of the art in action detection and localization. Finally, we propose some novel applications of the current technologies for activity detection in manufacturing assemblies.
1.2 Structure of the Review Process
The structure of the review process is as follows: We start by addressing the challenges faced by researchers in the field of intelligent assembly operation monitoring in Section 2, i.e., the motivation behind why we need to monitor human-centric assembly operations autonomously. In Section 3, the methodologies developed by researchers to detect and monitor human activities were discussed. The monitoring approaches were classified based on the sensors used: body-worn or vision cameras. Within body-worn sensor-based monitoring, the generic human activity detection methodologies were discussed and followed by a review of methodologies specific to manufacturing assemblies. Similarly, within vision camera-based monitoring, the current state of the art in detecting and localizing actions from video cameras using deep learning and machine learning was introduced and followed by a review of the methodologies developed for monitoring assembly operations. In Section 4, the evaluation metrics commonly used in action detection and localization studies, and assembly monitoring were explained. Additionally, some of the common datasets used for activity detection and localization were introduced. In Section 5, the inferences from all the papers reviewed were discussed in the context of monitoring human-centric assembly operations, and finally, in Section 6, future research directions were proposed.
2 Motivation
2.1 Challenges
Human activity recognition in a human-centric assembly operation helps in the following ways [ 7]:
ŌĆó Identifying the challenges faced by the human operators in an assembly workstation. ŌĆó Differentiate and classify different assembly steps. ŌĆó Track and measure the overall progress of assembly SOP steps. ŌĆó Ensure compliance with the work regulations. ŌĆó Ensure adherence to safety practices and regulations.
To monitor a human-centric manufacturing assembly operation effectively and completely it is required to address the abovementioned items.
In manufacturing, 40% of the cost and 70% of production time fall upon the assembly of intermediate components and final products [ 7], where much of the work was still being performed manually with little to no automation. This is true for the case of both high mix low volume and low mix high volume manufacturing enterprises. Activity recognition and action localization have been a topic of interest with a growing number of videos on online platforms and social media. They help in understanding the actions performed by detecting, classifying, and localizing the actions performed. Human activity recognition, when it comes to a manufacturing assembly operation, has the following challenges:
ŌĆó Activity recognition is working well in a laboratory setting. The transfer of knowledge from the laboratory to industries is a challenge. ŌĆó The models used for the study are data-hungry [8], and huge datasets were used to train them [9,10]. ŌĆó Typical action localization studied in the literature involves identifying the start and end time of an action in an untrimmed video. Real-time localization of actions is common for manufacturing industries and is not studied. ŌĆó The safety and privacy concerns of the industries might not allow the usage of body-worn sensors [7]. ŌĆó Detection of non-value added (NVA) activities is challenging as they cannot be used in the explicit training of the deep learning models.
2.2 Activity Recognition in Industries
Aehnelt et al. [ 7] stated that the activity recognition system for manufacturing assembly operations requires robust and reliable technologies which identify human activities even at smaller granularities. They summarized their observation into four generic requirements:
ŌĆó Modelling and recognition of different activity granularities ŌĆó Plausibility of recognized activities ŌĆó Reliable recognition and fallback strategies ŌĆó Consideration of industrial safety and privacy
Additionally, based on the work conducted by us and other authors [ 11, 12], it was identified that a reliable assembly monitoring system should also be able to identify the NVA activities in the assembly workstations. In a typical assembly workstation, around ~30% of the time was spent on NVA activities, hence a robust monitoring system should be able to classify the value added (VA) and non-value added (NVA) activities.
3 Existing Methodologies
In this section, the existing methodologies, and approaches to detect and localize actions will be reviewed. The domain of application for action detection and localization will include manufacturing assembly operations but may not be limited to it. Additionally, in this section, we aim to draw a contrast between the current state of the art for action localization and their prospective applications towards manufacturing assembly operations. Action detection refers to the ability to detect the action from the sensor signals, whereas action localization refers to the ability to localize the detected actions thereby helping in identifying the start and end times.
3.1 Body-worn Sensor Monitoring
Some of the early works in activity detection using body-worn sensors [ 14ŌĆō 16], but these works do not clearly state how the developed techniques will perform in a real-world [ 17]. Bao and Intille [ 17] collected data using 5 biaxial accelerometers from 20 subjects, who were asked to perform a sequence of everyday tasks. Several classifiers were applied to extracted features with the decision tree performing the best at 84%. Activity recognition is common in wearable computing communities [ 18ŌĆō 21]. Recognizing human activities are fundamental to providing healthcare and assistance services. Maekawa et al. [ 22] used hand-worn magnetic sensors to recognize the activities performed for the assisted living of the elderly, and home automation. The application of activity recognition in manufacturing industries is gaining traction in recent times. Maekawa et al. [ 23] developed an approach for measuring the lead time of assembly operations and estimating the start times. Using wearable sensors, the authors of the work identified the repetitive patterns in the sensor data that occurs once every operating period. Based on the occurrence of these patterns (motif), the start time and lead time of each period were then estimated. Similar and extended approaches to measuring the lead time using wearable sensors were also studied [ 24, 25]. The key advantage of the above studies is that they are unsupervised and there is no requirement for training data generation. Identifying the motif requires knowledge of the process model and its predetermined standard lead time. The process model here contains the process instructions, which are documents that describe the flow of the assembly operation and provides detailed instruction on the process. These process instructions are used to determine the candidate segments for the motifs. Unexpected events in an assembly operation are always a possibility, hence, Xia et al. [ 26] developed an approach to recognize activities by identifying motifs even when outliers are present in the data. With the advent of deep learning and machine learning technologies, human activity recognition using wearable sensors has been studied extensively. In a study conducted by Attal et al. [ 13], three inertial sensors were worn by healthy individuals at key points of upper/lower body limbs (chest, right thigh, and left ankle). The data were collected on 12 different human activities using the three sensors, and four supervised and three unsupervised machine learning algorithms were used to classify them. The human activity recognition process is shown in Fig. 2. Ermes et al. [ 28] used wearable inertial sensors to recognize daily activities using Artificial Neural Networks (ANN). Several survey articles have also discussed the application of body-worn inertial sensors on human activity detection [ 29ŌĆō 31]. The placement of sensors for human activity detection is a challenge, as there is no single location that can provide good results irrespective of the action performed. Multi-sensor accelerometer system was able to perform better than a single-sensor system, owing to its ability to capture complex motions at different locations on the human body [ 32]. Cleland et al. [ 27] conducted an investigation to identify the optimal locations for acceleration sensors to best detect everyday activities. The prospective sensor locations identified by the authors can be seen in Fig. 3. In addition to optimal sensor placement location identification, the work also aims to compare different machine learning models and determine the impact of the combination of triaxial acceleration sensors on the detection performance. It was identified that when it comes to everyday activities, the sensor located on the hip had the most impact. The impact of sensor type and sensor location for action detection in human-centric assembly operations is even greater, as each assembly operation is unique consisting of complex actions. Several works have studied the use of inertial and/or acceleration sensors to detect activities in a human-centric assembly line. Stiefmeier et al. [ 11], Ogris et al. [ 34] presented an approach of continuous activity recognition using motion sensors and ultrasonic hand tracking on a bicycle maintenance operation. The work also features the recognition of a ŌĆ£NULLŌĆØ class corresponding to the NVA activities. Koskim├żki et al. [ 35] used wrist-worn inertial sensors to detect common assembly operation tasks like screwing, hammering, spanner use, and power drilling. The data were collected from the sensors at a sampling rate of 100 Hz and were labeled using a video camera overlooking the assembly workstation. k Nearest Neighbors (k-NN) algorithm was used to classify different assembly actions with an overall accuracy of 88.2%. The authors of this work have also defined a ŌĆ£NULLŌĆØ class to account for actions other than assembly tasks. As an extension of the previous work, Koskim├żki et al. [ 36] identified the actions performed using wrist-worn sensors, and state machines were used to recognize completed tasks by searching continuous unvarying activity chains. Similar works for human-centric assembly monitoring can be seen in [ 33, 37]. Nausch et al. [ 33] discusses the identification of measurement parameters for sensors used in assembly monitoring along with an approach to process signals from Internet of Things (IoT) sensors. Sensor characteristics that can be used to measure an assembly environment, along with their relationship to the assembly process itself can be seen in Fig. 4 and 5. Studies have also been conducted where in addition to acceleration sensors, other sensors like microphones, Radio Frequency Identification (RFID), etc., have also been used. Lukowicz et al. [ 38] used microphones to identify assembly activities. The distinct sounds emitted upon using tools were used to classify different activities. Stiefmeier et al. [ 39] developed a fully integrated jacket consisting of seven (Inertial Measurement Unit) IMU sensors, Fig. 6, to detect worker actions and provide insights on their activities in real-time. The authors conducted a case study in a car manufacturing plant in Europe and summarized the lessons learned which fall under these three domains,
ŌĆó Data Acquisition and Annotation: Synchronizing and annotating the data stream across the multitude of sensors on the jacket. ŌĆó Sensors: Embedding of sensors to enable unobtrusive activity sensing. ŌĆó Gesture Segmentation and Classification: Multimodal segmentation, where information from one sensor was used to segment the data from another sensor.
Deep learning models have also been used to detect human activities in manufacturing assembly operations. Tao et al. [ 40] used IMU and Surface electromyography (sEMG) from an armband (Myo) to evaluate workersŌĆÖ performance. A convolution model was used to classify the activities. The overview of the activity recognition method the authors proposed can be seen in Fig. 7. Tao et al. [ 41] studied the importance of sensor location on the human body for different activities using an attention-based sensor fusion mechanism. Some sensor fusion approaches which incorporated information from the IMU signals and camera video stream was also been used to detect human actions in an assembly line [ 42], Fig. 8. In addition to IMU sensors/body-worn sensor monitoring, several studies have been conducted that uses RGB (Red, Green, and Blue) sensors for human activity detection. Some survey articles that go over these studies are [ 43ŌĆō 45]. Chen et al. [ 46] conducted a survey that explores the studies that involve the simultaneous use of both depth and inertial sensors for human activity recognition. The authors of the works state that the simultaneous use of both sensors helps improve detection accuracy, as seen in [ 42]. The wearable sensors can only sense the activity performed locally; it is challenging to detect activities that involve multiple body parts. At the same time, data from video sensors can suffer from occlusions. Hence, as previously stated and shown in Fig. 8, Tao et al. [ 42] used a combination of IMU sensors and video cameras to detect and actions in an assembly workstation. The data from each of the sensor modalities were processed using deep learning models and the softmax probabilities are fused together before making the final prediction. So far, we have seen approaches that aim to monitor human activities using body-worn sensors. Most of the studies conducted involved the use of acceleration and/or IMU sensors. In some cases, researchers have also explored the use of other sensors like magnetic, RFID, EMG, ultrasonic, etc. The location of the sensors on the human body is important to recognize the activity being performed. Identifying the right location is challenging, as they depend on the type of activity performed, and defining a universal sensor location might not be practical. To overcome the constraints, researchers have also studied a multi-sensor approach where data from multiple sensors were fused for inference. For analyzing the sensor data, machine learning, and deep learning were predominantly used. Studies were also conducted to compare between different algorithms that were used. Some studies consider an out-of-lab setting where the data were collected from activities without a controlled lab setting. Many of the studies do not focus on the challenges associated with body-worn sensors for day-to-day operations. In the next section, we will discuss a visual monitoring approach where human activities are detected in a non-contact fashion.
3.2 Vision Sensor Monitoring
Detection of actions from videos has been a topic of interest in deep learning communities. Temporal action localization involves the process of detecting the actions and localizing them, precisely, identifying the actions by classifying them among the classes, followed by determining the start and end times of a particular human action.
To better understand the actions performed from video data, feature extraction is important. The feature extraction process can be divided into local feature extraction and global feature extraction [ 47]. Lowe, Dalal and Triggs [ 48ŌĆō 50] discuss the feature extraction process from static images, i.e., local features. Whereas temporal features are a combination of static image features and temporal information. Some of the traditional methods for action localization are discussed in [ 47]. Vision sensor-based monitoring leads to the generation of large volumes of data compared to the body-worn sensor-based monitoring. Additionally, for safety and privacy reasons it might be required to blur the faces of the assembly operators. Having a network of camera systems monitoring a multitude of assembly workstations could also mean that the threat actors could potentially gain access to these cameras. Hence sufficient cybersecurity measures should be put in place to prevent attacks.
3.2.1 Action Detection and Localization
Deep learning has had incredible breakthroughs in the image domain [ 51]. It has propelled researchers to explore the benefits of deep learning outside the image domain. Carreira and Zisserman [ 52] re-evaluated the state of the art architectures for action classification using a new Kinetics Human Action Video dataset. They introduced a new Two-Stream Inflated 3D ConvNet (I3D-ConvNet). The video classification models which are currently studied either has 2D or 3D convolutional layer operators. Carreira and Zisserman [ 52] drew a comparison between the different models with different layers on the classification of videos as can be seen in Fig. 9. The details of each model architecture will be discussed later in the paper. The dataset used in the study for comparison were UCF-101 [ 53], HMDB-51 [ 54], and Kinetics [ 10]. The 3D ConvNets can directly learn about the temporal patterns from an RGB stream, their performance can still be greatly improved by including an optical-flow stream. The Two-Stream Inflated 3D ConvNet (I3D-ConvNet) proposed by Carreira and Zisserman [ 52] was created by starting with a 2D architecture and inflating all the filters and pooling kernels, thereby adding a temporal dimension. After experimental evaluation, the following conclusions were made:
ŌĆó The benefit of transfer learning from videos is beneficial, as across the board, all the models performed well. ŌĆó 3D ConvNets can learn effectively from the temporal stream, but they can perform much better if we include the optical flow stream as well.
When monitoring assembly workstations, the odds are that a single manufacturing facility has multiple assembly workstations, hence, transfer across the assembly workstations can be beneficial. The transfer of learning from the open-source and available activity datasets to the assembly workstations is not studied in the current literature.
The use of convolution networks for video classification was explored in [ 55, 56]. Multiple approaches were proposed to extend the CNN into the time domain which was not its typical application domain. In this work, the authors consider the videos as a bag of short fixed-size clips. The authors proposed three broad connectivity patterns that would enable the processing of information from the video data, called Early Fusion, Later Fusion, and Slow Fusion, as seen in Fig. 10. The authors of this work also proposed a multi-resolution CNN architecture, where the input was divided into two streams - fovea stream and context stream, with the difference being in two spatial resolutions. This architecture was only applied for the single-frame connectivity pattern to speed up the training process to avoid any compromises in the model architecture. The architecture of the multi-resolution model can be seen in Fig. 11. From the evaluations, the authors found that the slow fusion model performs consistently better than the early and late fusion alternatives. The stacked frames approach [ 56] provided a way to use CNN for video classification but their approach was significantly worse than the best hand-crafted shallow representations [ 57]. Additionally, Karpathy et al. [ 56] found that the model working on individual video frames performs the same as the model acting on a stack of video frames. Simonyan and Zisserman [ 57] developed a two-stream CNN architecture for activity recognition, the two streams of information that were used involved optical flow (temporal information) and RGB frames (spatial information). The authors trained the spatial stream and the temporal stream separately and fused the softmax scores at the end, as they found this to avoid overfitting. Through the evaluation, the authors of this work made the following conclusion:
ŌĆó Pre-training followed by fine-tuning had the most impact on the final performance of the model. ŌĆó Temporal ConvNets alone significantly outperformed the Spatial ConvNets. ŌĆó Stacking RGB frames improves the performance by 4% over individual RGB frames. ŌĆó The Two Stream ConvNets had a 6% and 14% increase in performance over the Temporal ConvNet and Spatial ConvNet, individually.
Even though Karpathy et al., Simonyan and Zisserman [ 56, 57] use multiple video frames of input for action detection and classification, the convolution by itself was 2D. The difference in 2D and 3D convolution operations can be seen in Fig. 12. There is a growing need to generalize the approach to identify actions from videos as it will enable smoother adoption of the technologies by industries. Hence, studies have explored the prospects of generalizing spatiotemporal feature learning using 3D ConvNets [ 58]. The authors identified four prospects of video descriptors to be: (i) generic, (ii) compact, (iii) efficient, and (iv) simple. A 3D ConvNets (C3D) differs from a 2D ConvNets in that it selectively attends to both motion and appearance. After evaluating the C3D on the UCF101 dataset [ 53], the authors concluded that it could outperform 2D ConvNets, in addition to being efficient, compact, and extremely simple to use. The modeling of the long-range temporal information is challenging for typical convolutional models. This can be attributed to the fact that they operate on a single frame (spatial networks) or on short video snippets, i.e., a sequence of frames (temporal networks). In cases where the action sequence is long, long-range temporal information needs to be modeled. Wang et al. [ 59] designed a Temporal Segment Network (TSN) architecture such that it can capture long-range dynamics for action recognition. The reason was attributed to the segmental model architecture and sparse sampling. Similarly, Varol et al. [ 60] developed a model called LTC-CNN to process data on human actions at their full temporal extent. Through this work, they were able to extend the 3D CNNs to significantly longer temporal convolutions. In addition to Convolutional Networks (2D and 3D), several other architectures have also been tried to classify actions from videos. Yue-Hei Ng et al. [ 61] tried two different model architectures to combine the image information across a video over a long time period. The first architecture explores the use of temporal feature pooling, and the second architecture explores the use of Long Short Term Memory (LSTM) layers on top of convolutional layers. The data input to the model involves both raw RGB frames and optical flow information. The two models were then evaluated against the Sports 1M [ 56] and UCF-101 [ 53] datasets. Donahue et al. [ 62] developed a novel model architecture called the Long-term Recurrent Convolutional Network (LRCN). LRCN is particularly interesting as it can map variable length inputs to variable length outputs. Similar to the works from Karpathy et al. [ 56], Simonyan and Zisserman [ 57], which proposes the use of convolution layers to learn the features from a sequence of frames, Donahue et al. [ 62] can handle variable length of the input video frames. The sequence of frames, 16 in their case, was first passed into a CNN base followed by LSTM layers. The CNN base that was used in LCRN was AlexNet [ 51]. Similar approaches that use RNN to learn the temporal dynamics from extracted features are [ 63ŌĆō 66]. To realize a full-fledged assembly monitoring system, the detected actions must be localized. The localization process helps identify the step time for each individual assembly step within an assembly cycle.
3.2.2 Human Action Recognition in Manufacturing
The complexity and variety of manufacturing assembly operations demand the use of digital technologies to support and ensure the safety of human operators. Urgo et al. [ 68] used deep learning to identify the actions performed by assembly operators. A hidden Markov model was then used to identify any deviations from planned execution or dangerous situations. An industrial case study was conducted where the developed techniques were applied, and alarms were raised when the assembly operations were not completed. Chen et al. [ 67] developed two model architectures, one using 3D CNN and the other using a fully convolutional network (FCN), to recognize the human actions in an assembly and to recognize the parts from an assembled product, respectively. The data generation and the feature extraction process used by the authors can be seen Fig. 13. Chen et al. [ 69] used deep learning methods to recognize repeated actions in an assembly operation to estimate their operating times. The assembly actions were considered as the tool-object interaction and YOLOv3 [ 70] was used in detecting the tools. A pose estimation algorithm, Convolution Pose Machine (CPM) [ 71], was used to identify the human joint coordinates, which along with the identified tool-object interaction was used in estimating the operating times. The process involved is shown in Fig. 14. Lou et al. [ 72] used a two-stage approach to monitor manual assembly operations in real time. In the first stage, YOLOv4 [ 73] was used as a feature extractor to detect workersŌĆÖ sub-operations and form a feature sequence, in the second stage, a Sliding Window Counter algorithm was used to find the boundary points for counting the number of manual operations/sub-operations. Similar to the previous work, Yan and Wang [ 74] used YOLOv3 and VGG16 [ 75] networks to autonomously monitor manufacturing operations. Chen et al. [ 76] applied an image segmentation process to monitor assembly operations. The system was able to detect missing and wrong assemblies, and any errors in the assembly sequence or human pose information. The approach proposed here was post the assembly operation itself, and the inferences on the assembly quality were made on the end product. Xiong et al. [ 77] applied the two-stream approach developed by Simonyan and Zisserman [ 57] for human activity detection in an assembly scenario to detect and recognize human actions. The robustness of the two-stream approach under assembly variations and noise was tested. Additionally, the work also explores the application of transfer learning to enable knowledge transfer from pre-trained CNN on a human activity dataset to manufacturing scenarios. The flowchart of the training process and the transfer learning process can be seen in Fig. 15. Zhang et al. [ 78] developed a hybrid approach that involves bi-stream CNN and variable-length Markov modeling (VMM) to recognize and predict human actions in an assembly. Human-robot collaboration (HRC) has become popular recently [ 79]. HRC combines the strength, repeatability, and accuracy of robots with the high-level cognition, flexibility, and adaptability of humans to achieve an ergonomic working environment with better overall productivity [ 80]. Several works have also been conducted that explore human action recognition in the context of human-robot collaboration (HRC) [ 79, 81, 82]. The details of these works are beyond the scope of this review. The detection of non-value added (NVA) activities in human-centric assembly operations autonomously are challenging. NVA activities correspond to all activities that do not form a part of the assembly SOP steps. These activities can happen at any point in time and the developed monitoring system should be robust enough to identify as not being a part of assembly SOP steps. Ogris et al. [ 34], Koskim├żki et al. [ 35] intentionally introduced the ŌĆ£NULLŌĆØ class to closely reflect an actual assembly operation. In both the above cases, pattern-matching approaches were used to separate them from the assembly SOP steps. But in a typical assembly process, it is not always possible to generate data on the ŌĆ£NULLŌĆØ category, as it needs to account for all possible scenarios other than the assembly SOP steps. Selvaraj et al. [ 12] followed an energy-based Out-Of-Distribution (OOD) detection approach to identify all NVA activities as OOD instances. The dataset used for the work was collected from an assembly line with around 51.8% of the time spend on NVA activities. Using the energy-based OOD detection approach, the in-distribution instances, corresponding to the assembly SOP steps, and OOD instances, corresponding to the NVA activities can be separated as seen in Fig. 16. OOD detection in deep learning has been gaining traction in recent years. Hendrycks and Gimpel [ 83] established a simple baseline for the detection of OOD instances from the probabilities of the softmax distribution studied. The concept behind this approach is that the correctly classified examples tend to have greater maximum softmax probabilities than the erroneously classified OOD examples. The softmax probabilities in a typical trained neural network for both in-distribution and OOD instances are close to each other as an artifact of the training process. Hence, Liang et al. [ 84] used a temperature scaling in the softmax function [ 85, 86], and added small controlled perturbations to the inputs to enlarge the softmax score gap between the in- and out-of-distribution. Liu et al. [ 87] developed an energy score approach to improving the performance of OOD detection over the traditional approaches that use softmax scores, but it requires some instances of data corresponding to the OOD distribution during the deep learning model training process to create the energy gap. Finally, Cui and Wang [ 88] reviewed OOD detection approaches based on deep learning that is currently available in the literature.
4 Anomalies in Assembly Monitoring
In this section, an overview of what constitutes an anomaly in human-centric assembly operation is discussed. Throughout the literature, authors determine anomalies specific to their task in hand. In activity detection studies, anomalies detection ability of the monitoring system was evaluated by determining the number of correctly classified activities, whereas, in certain studies inability to perform an operation in the correct sequence was identified as an anomaly. Hence, in this section, we aim to summarize what constitutes an anomaly in a human-centric assembly operation. Additionally, we also provide a high-level overview of a real-time monitoring and guidance system.
For the case of human activity detection studies, anomalies correspond to inability of the models to detect the local actions. In certain cases, the anomalies also include a ŌĆ£NULLŌĆØ class which correspond to all activities outside the set of activity for an assembly workstation. Studies also evaluated the performance of the monitoring system depending on their ability to identify breaks in assembly sequence and missed steps. The anomalies, sequence breaks, and missed steps, help in determining the quality of the assembly operation performed by the human operators. Several studies have also used semantic segmentation or object detection approaches to assess the quality of the assembled product, post assembly operation. Finally, in addition to monitoring the assembly operation itself, studies have also monitored safety of operators in the assembly line and ensured that they follow safety practices.
Monitoring of assemblies help in detecting the anomalies in real-time. A high-level overview of a monitoring and guidance system was proposed in [ 12], as can be seen in Fig. 17. The system can look for operational anomalies like Sequence breaks and Missed steps in an assembly cycle, in addition to guiding the assembly operators by identifying the tools and components required at each assembly step. Alerts were raised using audio and visual cues to inform the operators of the anomalies as they happen.
5 Evaluation Metrics
In this section, an overview of several metrics used to evaluate the models for assembly action detection and localization is presented. The evaluation metrics are classified into Generic and Specific. Generic evaluations are common and are used external to action localization, whereas the specific evaluations are more catered to action localization studies and assembly monitoring. Performance metrics are fundamental in assessing the quality of the learned models. Ferri et al. [ 89] experimentally evaluated 18 different performance metrics that were commonly used to evaluate deep learning and machine learning models.
Accuracy: It is a classification metric used to evaluate the accuracy with which a model can classify different actions. Classification accuracy is the number of correct predictions made as a ratio of all the predictions. It is only suitable if there are an equal number of observations present in each class.
In certain cases, it is not always possible to have a balanced classification where all the classes have an equal number of observations. Hence, the metrics sensitivity-specificity and precision-recall are important.
Sensitivity: It is the true positive rate, which helps in identifying how well the positive class is predicted.
Specificity: It is the complement to Sensitivity, also called the true negative rate and helps in identifying how well the negative class is predicted.
Precision: Precision metric quantifies the number of correct positive predictions made from all positive predictions. It evaluates the fraction of correctly classified instances among the ones classified as positive [ 90]. Precision is not limited to binary classification problems. For the case of multi-class classification, TPs for every class c is summed across the set C.
Recall: Recall metric quantifies the number of correct positive predictions made from all correct positive predictions that could be made.
F-measure: F-measure combines both Precision and Recall. It is a single metric that summarizes the modelŌĆÖs performance. F1-measure weighs the Precision and Recall equally and is often used for imbalanced datasets.
Mean Average Precision mAP: Average precision is the average of Precision from all videos belonging to a particular class C. Mean average precision is the mean of average precisions across the testing dataset. It can be used to evaluate different models across the same dataset.
The metrics presented above can be used to evaluate the anomaly detection ability of the models used in assembly monitoring. The anomalies in an assembly are Sequence breaks and Missed Steps. The sequence break corresponds to a break in the sequence of operations within an assembly cycle, whereas, missed step (s) correspond to missing one or more assembly steps within an assembly cycle. The anomaly detection ability of the models can be evaluated using the above metrics. In addition to being able to detect anomalies, it is equally important to evaluate the ability of the models to accurately and precisely determine the step time and cycle time of the assembly SOP steps and assembly cycle, respectively. Some evaluation metrics that can be used to measure this ability are:
NMAE: Normalized Mean Absolute Error (NMAE) is the Mean Absolute Error (MAE) normalized by the mean of the actual value. The actual value for the case of assembly monitoring would be the human-inferred step time or cycle time.
IoU: Intersection over Union (IoU) in 1D is the overlap between the inferred time block and the actual time block. It helps in determining how effectively the model can localize the detected actions.
5.1 Datasets
In this section, the datasets used in various studies to either detect and classify actions or localize them are discussed. Finding the right data to train machine learning and deep learning models could be challenging and it is important to choose the right one depending on the application. The datasets discussed are categorized by the type of sensor used to collect them.
5.1.1 Body-worn Sensors
In this section, the data were collected by placing sensors at different locations of the human body.
Skoda Dataset [ 91]: The data were collected using a 3-axis accelerometer sampled at 100 Hz in a car maintenance scenario. The sensors were placed on both the right and left hands, a total of 20 sensors. The activities performed were related to a car manufacturing/assembly operation.
PAMAP2 [ 92]: This data was collected from three IMU sensors worn on the chest, wrist, and ankle. There was a total of 12 activities that were performed. The activities were (1) lying down, (2) sitting, (3) standing, (4) walking, (5) running, (6) cycling, (7) nordic walking, (8) ascending stairs, (9) descending stairs, (10) vacuum cleaning, (11) ironing, and (12) jump roping. A total of 9 different subjects were used in the data collection studies.
Daily Sports [ 93]: The data contains IMU and magnetometer data of 19 classes comprised of every day and sports activities ((1) sitting, (2) standing, (3ŌĆō4) lying on the back and right side, (5ŌĆō6) ascending and descending stairs, (7) standing still in an elevator, (8) moving in an elevator, (9) walking, (10ŌĆō11) walking on a treadmill, (12) running on a treadmill, (13) exercising on a stepper, (14) exercising on a treadmill, (15ŌĆō16) cycling on an exercising bike, (17) rowing, (18) jumping, (19) playing basketball). The IMU devices were placed on the torso, right arm, left arm, right leg, and left leg. The data were collected from 8 different subjects.
Sensor Activity Dataset [ 94]: The data here were collected from IMU sensors and consisted of 7 activities. The activities were (1) biking, (2) stairs descending, (3) jogging, (4) sitting, (5) standing, (6) stairs ascending, and (7) walking.
Opportunity [ 95]: A dataset of complex, interleaved, and hierarchical naturalistic activities collected in a very rich sensor environment. A total of 72 sensors were used with different modalities. The data were collected from 12 individuals performing their morning activities, leading to a total of 25 hours of sensor data.
Opportunity ++ [ 96]: This is an extension of the ŌĆ£opportunityŌĆØ data mentioned above. Opportunity++ addresses these limitations by enhancing the ŌĆ£opportunityŌĆØ dataset with previously unreleased video footage and video-based skeleton tracking.
5.1.2 Video Data
The datasets below consist of recorded video data of human actions. Some of them contain only one action per video clip whereas some contain multiple actions in a single clip.
HMDB-51 [ 54]: The dataset consists of 51 action classes with each class containing at least 101 clips for a total of 6,766 video clips. The clips were extracted from various sources from the internet including YouTube. The dataset contains short video clips of human actions that are a representative of everyday actions. The action categories can be grouped into 5 categories: 1) General facial actions, 2) Facial actions with object manipulation, 3) General body movements, 4) Body movements with object interaction, and 5) Body movements for human interactions.
UCF101 [ 53]: The dataset consists of 101 action classes categorized by five types: Human-Object interaction, Body Motion only, Human-Human interaction, Playing Musical Instruments, and Sports. This dataset is an extension of UCF50 [ 97]. UCF101 consists of a total of 13K clips and 27 hours of video data.
ActivityNet [ 9]: The dataset consists of a total of 203 activity classes with an average of 137 videos per class. The dataset contains both untrimmed and trimmed videos. ActivityNet includes wide range of activities that are of interest to people in their daily living.
Kinetics [ 10]: This dataset consists of 400 human action classes with at least 400 video clips for each action. Each clip lasts about 10s and contains a variety of classes. Hara et al. [ 98] state that this dataset could be used to train large-scale models. The actions in the dataset are human focused and covers a broad range of human-object interaction and human-human interactions. Compare of UCF101 [ 53] and HMDB-51 [ 54] Kinetics data is large and contain sufficient variation to test and train current generation activity detection models.
Assembly101 [ 99]: The dataset consists of people assembling and disassembling toy vehicles. The videos were recorded from 8 static and 4 egocentric viewpoints, totaling 513 hours of footage. The data were annotated with more than 1M action segments, spanning 1380 fine-grained and 202 coarse action classes, Fig. 18. In addition to creating a new open-source dataset, the authors of the work also provide a review of currently available datasets similar to Assembly101. The MECCANO dataset [ 100], in particular, is close Assembly101 dataset.
IKEA ASM [ 101]: A large-scale comprehensively labeled furniture assembly dataset for understanding task-oriented human activities with fine-grained actions. The dataset contains 371 furniture assembly videos and is multi-view and multi-modal - comprising RGB frames, depth information, human pose, and object segmentation.
In addition to the datasets mentioned above, some instructional video datasets that closely relate to assembly operation can be found in [ 102ŌĆō 105]. Other datasets which may not contain a variety of action classes as the ones mentioned above but are commonly used are KTH [ 106], Weizmann [ 107], IXMAS [ 108], etc.
6 Discussions
Human-centric manufacturing is extremely valuable with the advent of AI. In addition to monitoring human-centric assembly operations, it can ensure to maintain worker safety and ergonomic practices in manufacturing industries. With the advent of the European Commission releasing its policy brief - ŌĆ£Industry 5.0 - towards a sustainable, human-centric and resilient European industryŌĆØ [ 109], human centricity in manufacturing industries has taken prominence. In [ 80], human centricity in future smart manufacturing with a focus on component assembly is discussed. The future of human-centric assemblies in the factories of the future was illustrated in Fig. 19.
6.1 Considerations
Monitoring of human actions and localization has been studied extensively. Different sensor modalities have been explored to better detect and localize human actions. Currently, there is no single approach that can be applied universally across all assembly operations in a manufacturing industry. Some factors to consider when developing an intelligent assembly monitoring system are listed below depending on the type of monitoring system.
Using body-worn sensors to monitor assembly operations:
ŌĆó The data collection process could be challenging. There are not many datasets available that are specifically catered to assembly monitoring. The reason could be partly attributed to the fact that each assembly operation is unique and using a single representative data is challenging. ŌĆó It is beneficial to collect data in a training/prototyping setup where the environment could be augmented extensively. This could be a bane as it might become challenging to transfer knowledge from prototype to actual assembly lines. ŌĆó By using a multitude of sensors on the human body such that it can map the motion of each appendage, the human action can be recognized with near-perfection results. Having a large number of sensors can make the modeling process difficult, additionally, it can also be challenging to synchronize the data collected, both during the training and inference phase. ŌĆó Generalizing the monitoring process by fixing the number of sensors required to detect all the necessary actions within an assembly line or facility containing multiple assembly workstations can be beneficial. It enables easier adoption, deployment, and troubleshooting for manufacturing industries. ŌĆó In assembly workstations it might not always be possible to attach a multitude of sensors to the operators. It can be a safety concern as it can hamper their day-to-day activities, and in certain cases, it can potentially damage the part being assembled. For instance, when assembling electronic components, the static from the sensors can potentially harm the component being assembled. ŌĆó Management of the monitoring system that is deployed across the manufacturing facility, and across a multitude of operators can be challenging. It is up to the operators to ensure that the sensors are always operational. Additionally, they might also need to ensure to keep them charged when not used. ŌĆó The calibration of the sensors could potentially drift over time. It is important to ensure that the models used to make the predictions can accommodate for the drift in the sensor calibration. ŌĆó The monitoring system used should be robust enough to accommodate the anthropometric variations associated with the human operators.
Non-contact approach to monitoring manufacturing assembly operations using vision-based systems:
ŌĆó Vision-based systems such as RGB cameras or depth cameras are cost-effective and easy to deploy. ŌĆó Continuous and real-time monitoring of assembly workstations can lead to the generation of large data. Hence, data handling and management practices might become important. ŌĆó The large volumes of data can potentially slow down the prediction/inference process. Hence, computationally efficient data processing and model development practices, along with high-performance computing (HPC), can enable real-time monitoring of assembly workstations. ŌĆó The sampling rate for the videos determine the shortest action that could be detected in an assembly workstation. In a study conducted by Selvaraj et al. [12], 30 frames-per-second (FPS) was sufficient to detect all human actions in a human-centric assembly operation. ŌĆó The position of the vision system can greatly affect the performance of the monitoring system. In cases where the optical flow is computed as part of the feature extraction process, it is beneficial to ensure that the camera system is firmly secured. ŌĆó The calibration of the camera system and the focus is important to improve the performance of the model (s). ŌĆó Vision systems can be sensitive to changes in the illumination of the workplace. Although there are no studies that specifically evaluate the degradation of performance with the changes in the illumination, it might be in the best interest to ensure that the workplace illumination does not vary over the course of the assembly operation. ŌĆó Vision system could potentially be impacted by the variability associated with the assembly workers and clothes [12]. Hence, care should be taken to either collect data such that it encompasses this variability or approaches should be developed to disassociate the human operators, clothing, etc., from the modelling process. ŌĆó Security and privacy practices can be important to ensure assembly operator privacy. ŌĆó Finally, the vision-based system can remove the burden on the assembly operators such as wearing sensors on the body, periodic maintenance, and charging requirements.
6.2 Future Research directions
The future research direction for intelligent monitoring of human-centric assembly operations is presented in this section:
ŌĆó Generalization of the monitoring system. In a typical manufacturing industry comprising multiple assembly lines with multiple assembly workstations, it can become overwhelming to develop custom models for each workstation. Hence, the work toward the generalization of the monitoring system and prediction models could enable the widespread adoption of these technologies by manufacturing industries. ŌĆó Majority of the work in the current literature focuses on detecting and counting repetitive actions in an assembly. Monitoring of step time and cycle time of an assembly operation is equally important as enables the industry to troubleshoot bottlenecks and track lead time variations. ŌĆó It is not always possible to account for every possible scenario that could potentially happen in an assembly workstation, as a human factor is involved. As it is not possible to generate training data accounting for all possible scenarios. Hence, approaches that can detect these unknown and unforeseen events not to be a part of assembly SOP steps are important. ŌĆó In human-centric assembly operations, the assembly workstations can be dynamic, meaning, the location of the components and tools can potentially change over time. Additionally, it is also possible that there could be changes in the human operators working at a station. A robust model should be able to accommodate or adapt to these changes through a continuous and life-long learning process. ŌĆó Integration of the process physics behind the assembly operations, i.e., the information on the sequence of operations, constraints on the components being assembled (for example, Component-B can only be added to the main part after adding Component-A, as there is a physical constraint), etc. This information can potentially improve the robustness and the performance of the models used in the inference process if they can be captured.
Fig.┬Ā1
The paradigm of the humans in the industry [ 6] (Adapted from Ref. 6 with permission) 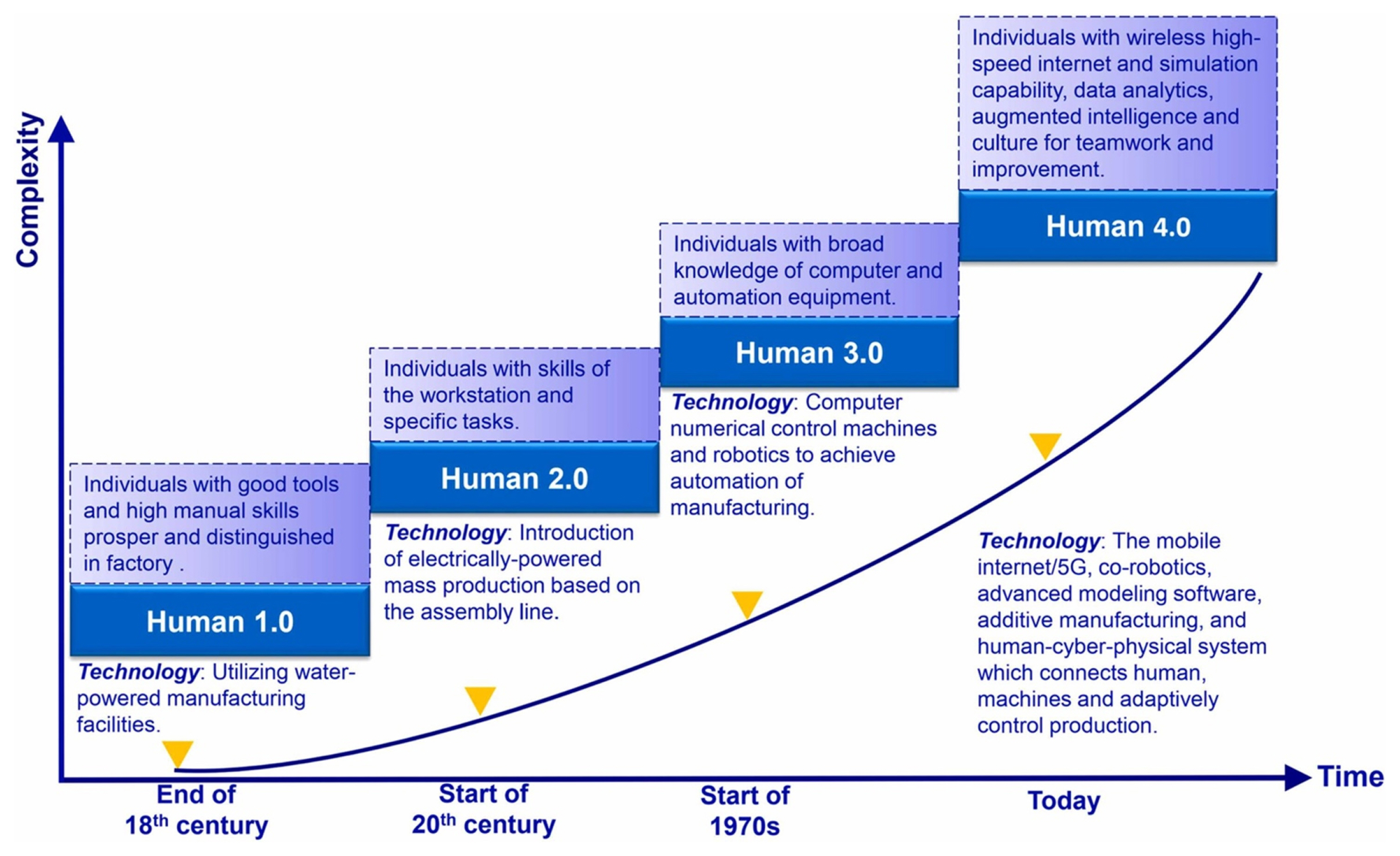
Fig.┬Ā2
Process involved in human activity modeling [ 13] (Adapted from Ref. 13 on the basis of OA) 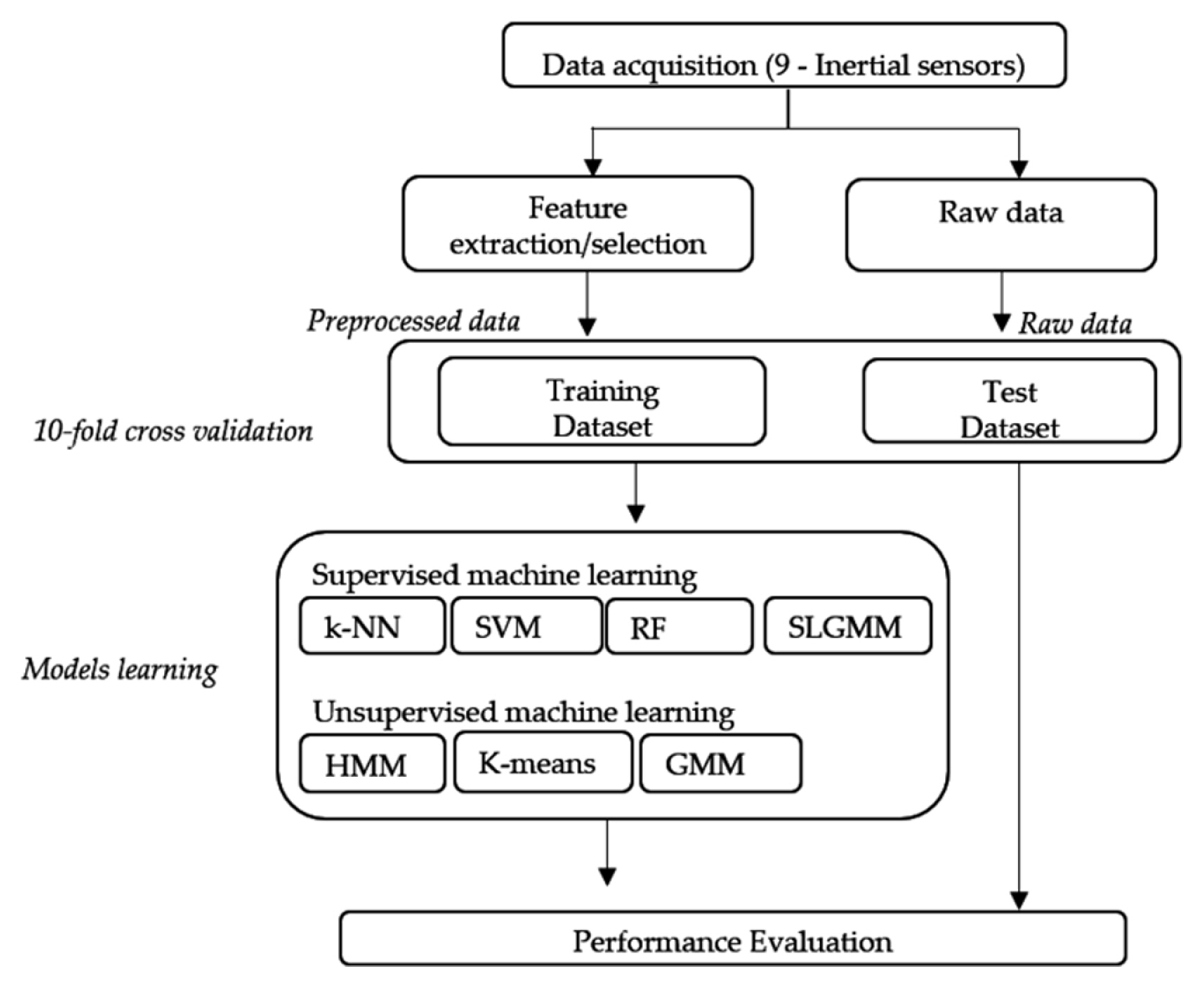
Fig.┬Ā3
Acceleration data was sampled at 50 Hz from 6 locations simultaneously [ 27] (Adapted from Ref. 27 on the basis of OA) 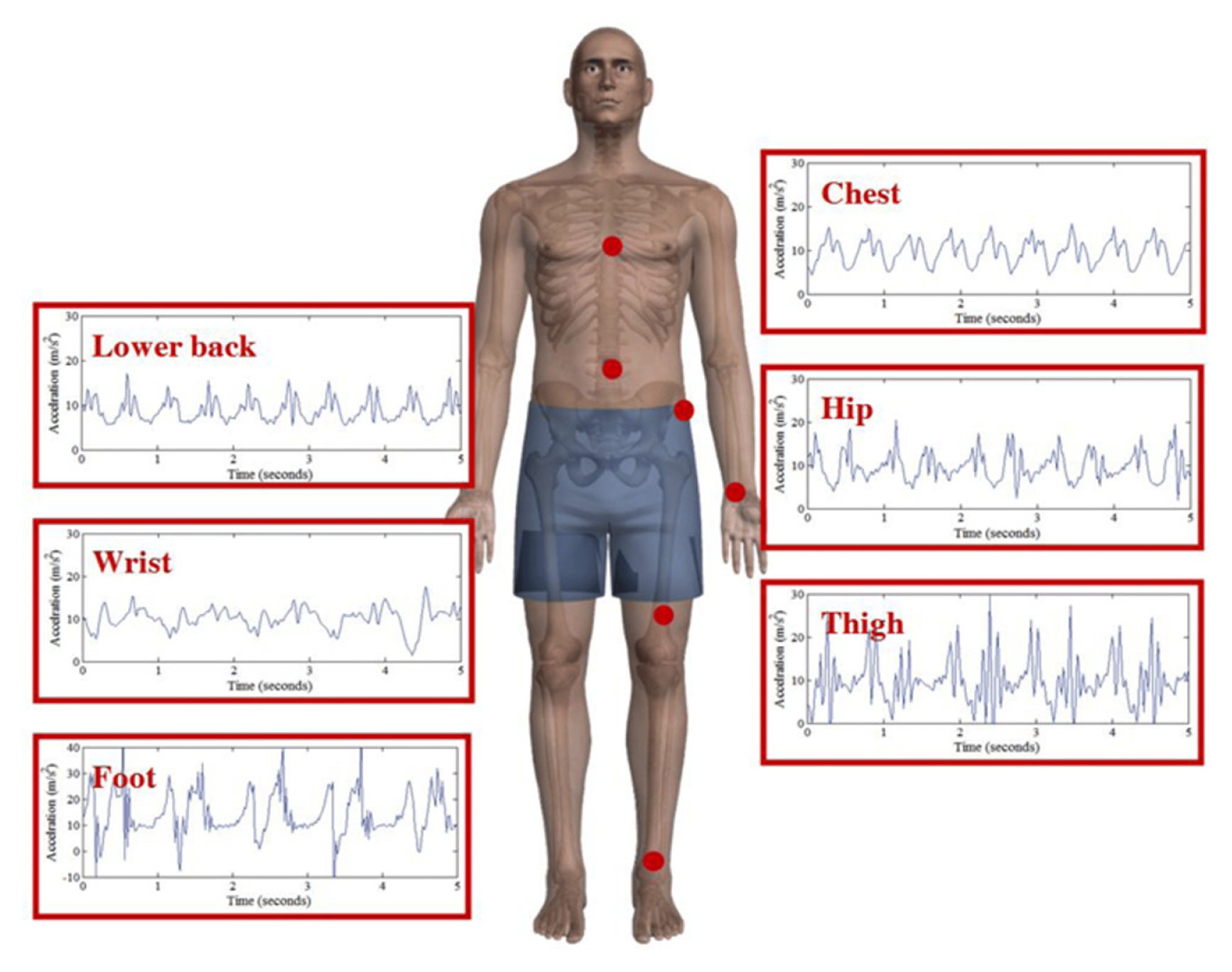
Fig.┬Ā4
Sensor characteristics [ 33] (Adapted from Ref. 33 on the basis of OA) 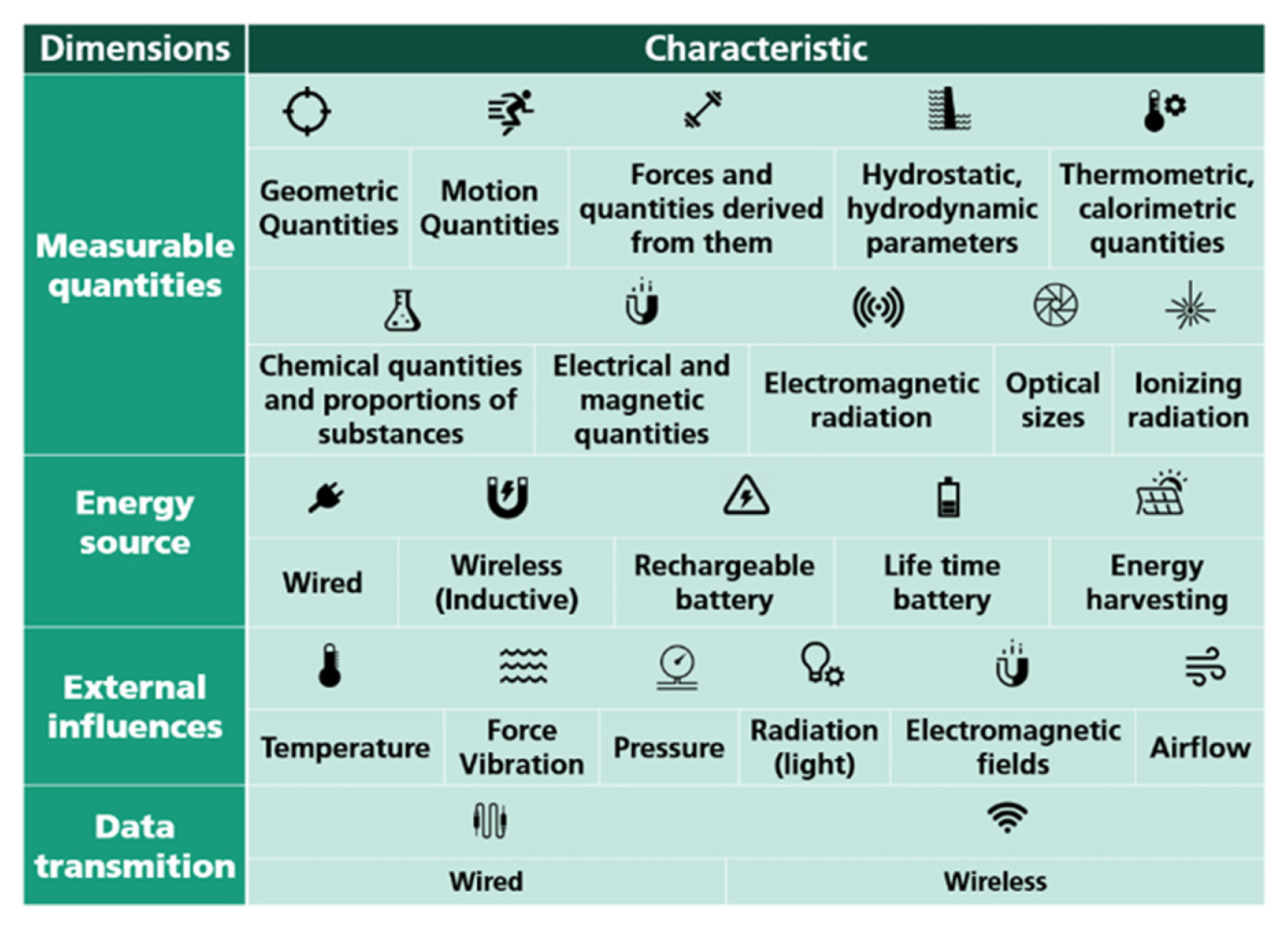
Fig.┬Ā5
Sensor measurement points in assembly [ 33] (Adapted from Ref. 33 on the basis of OA) 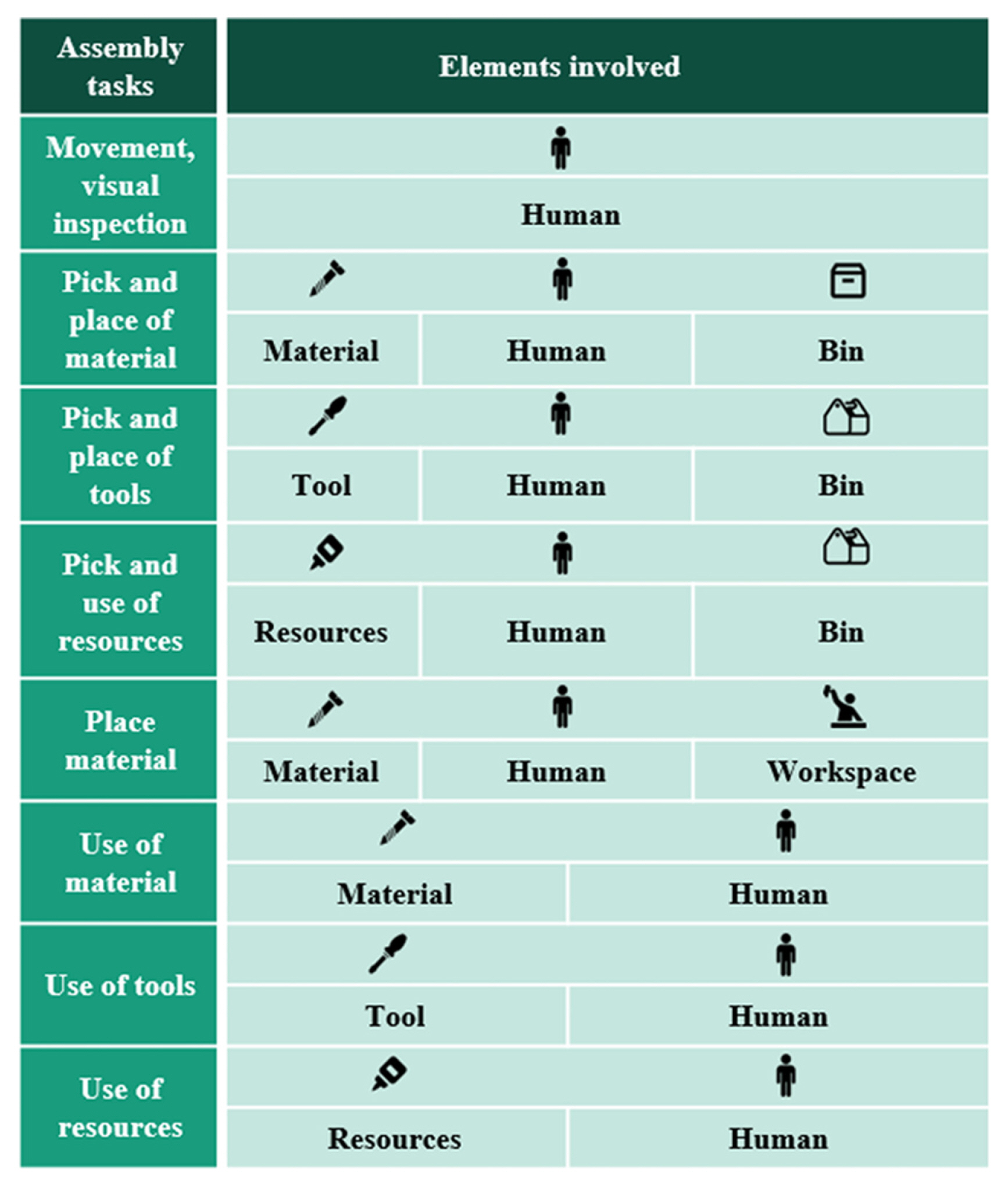
Fig.┬Ā6
Sensor jacket to monitor human activities in a car manufacturing industry [ 39] (Adapted from Ref. 39 on the basis of OA) 
Fig.┬Ā7
Overview of worker activity recognition method [ 40] (Adapted from Ref. 40 on the basis of OA) 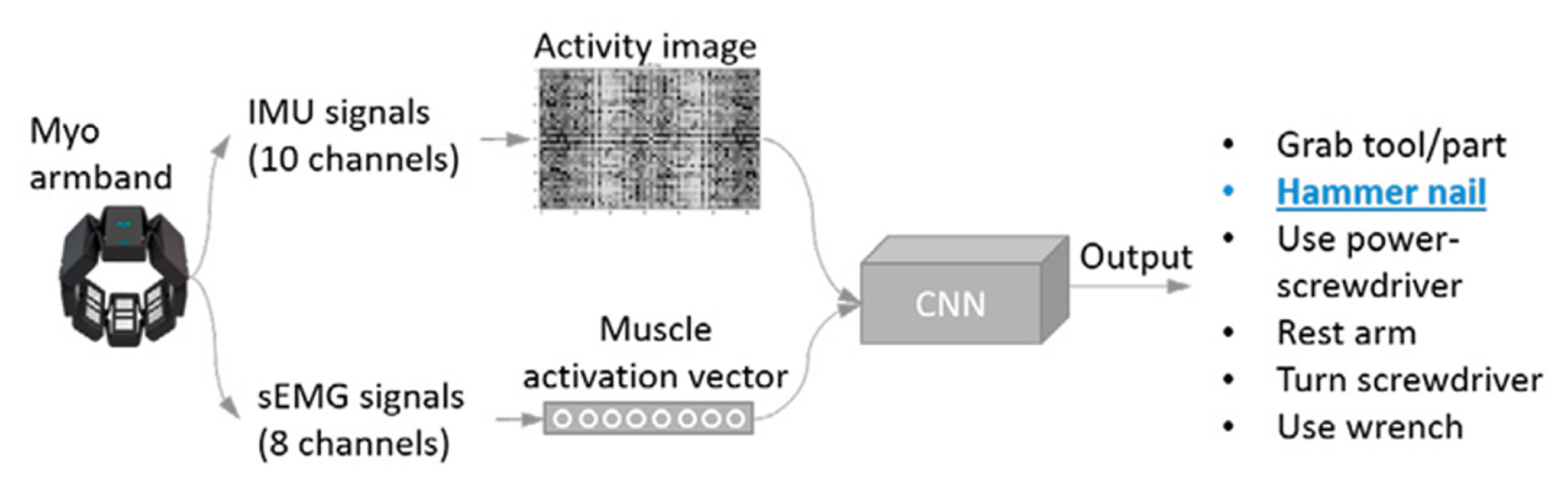
Fig.┬Ā8
Multi-modal approach for worker activity recognition [ 42] (Adapted from Ref. 42 with permission) 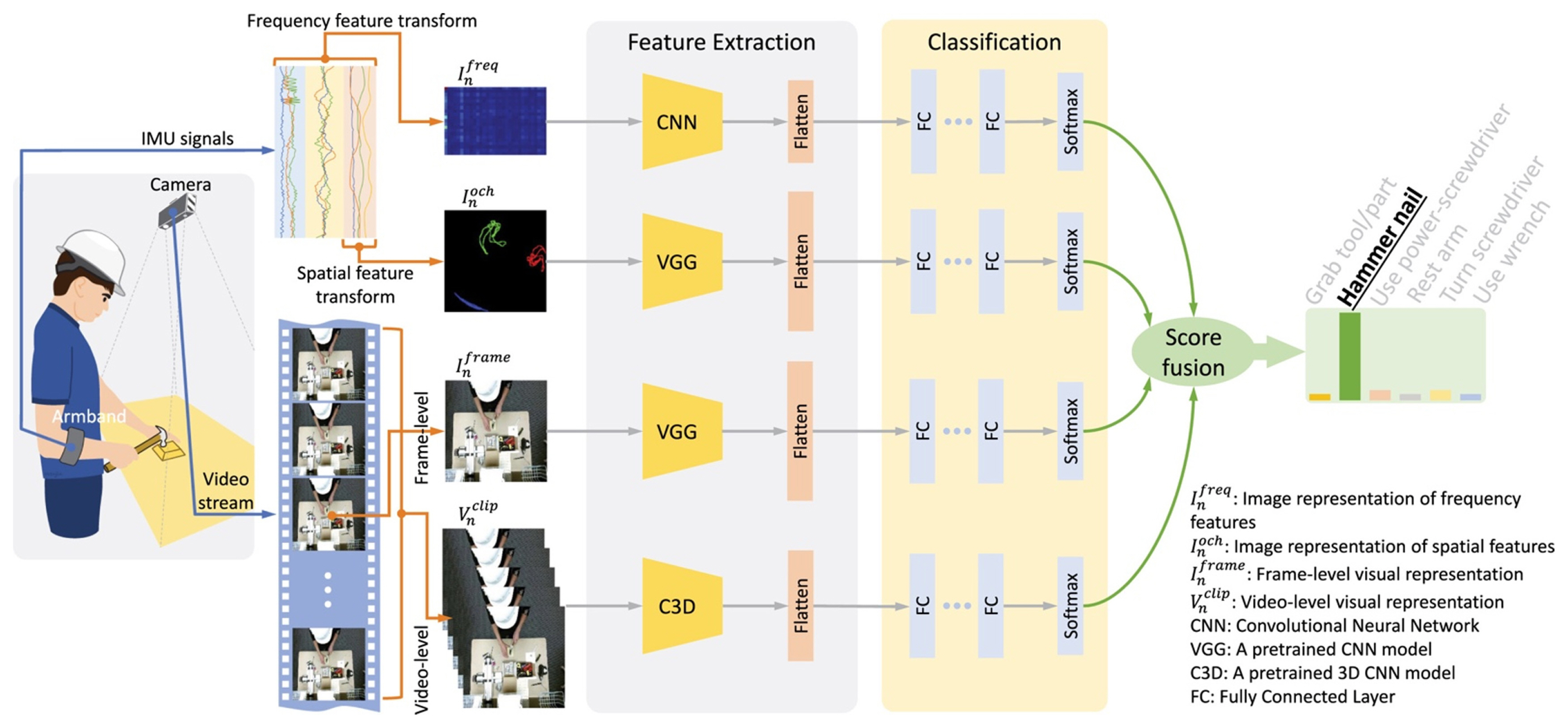
Fig.┬Ā9
Video classification architectures compared in, [ 52] (Adapted from Ref. 52 on the basis of OA). K stands for the total number of frames in a video, whereas N stands for a subset of neighboring frames of the video 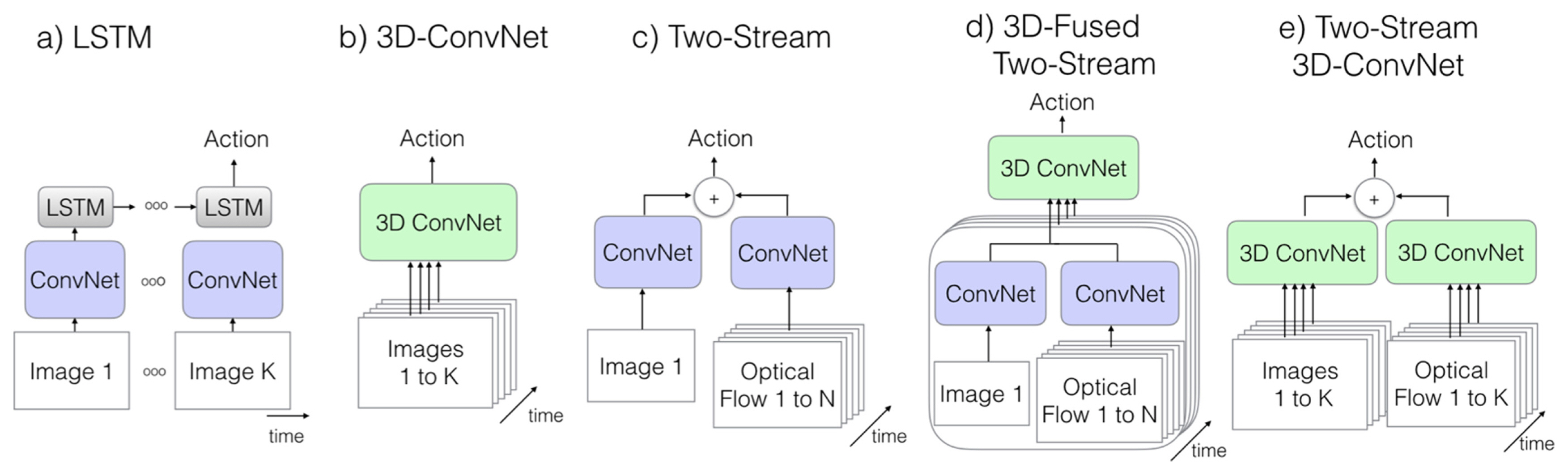
Fig.┬Ā10
Approaches explored in Karpathy et al. [ 56] (Adapted from Ref. 56 on the basis of OA) for information fusion over the temporal dimension 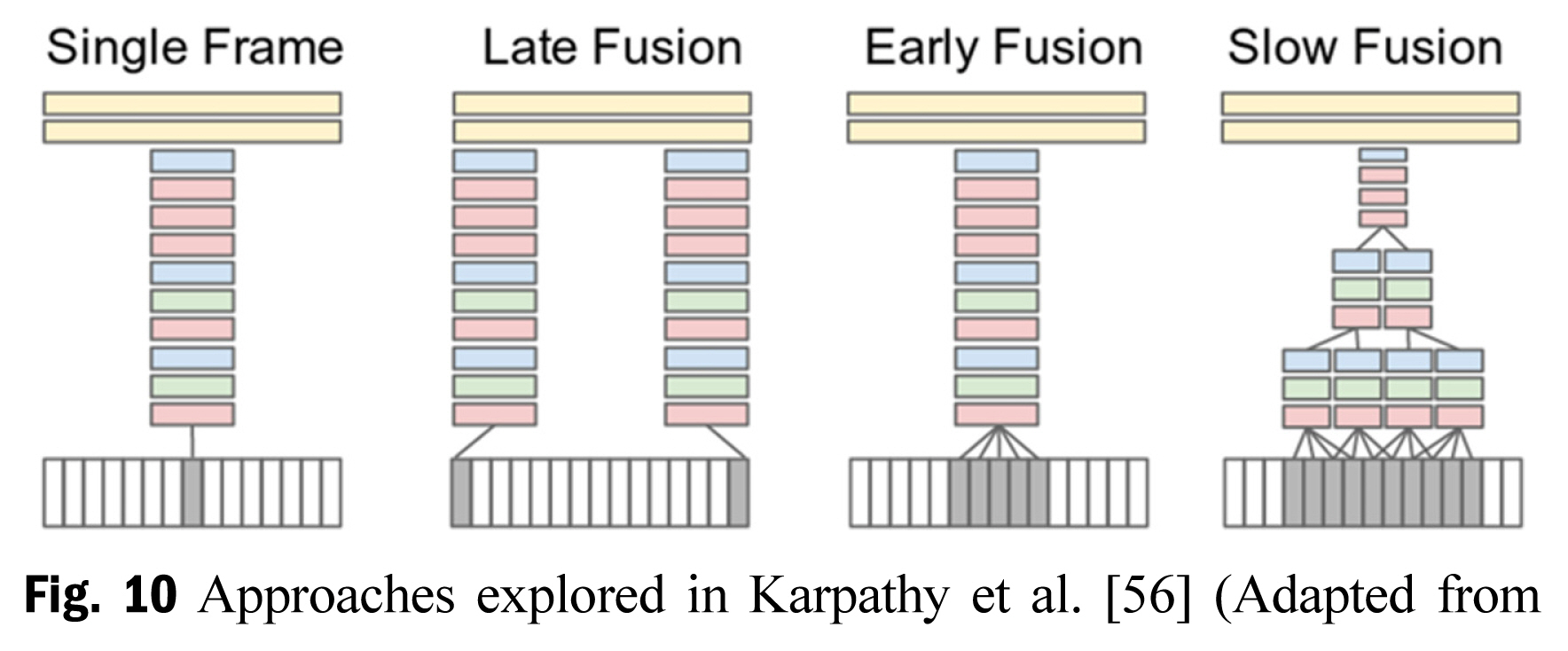
Fig.┬Ā11
Multi-resolution CNN [ 56] (Adapted from Ref. 56 on the basis of OA) 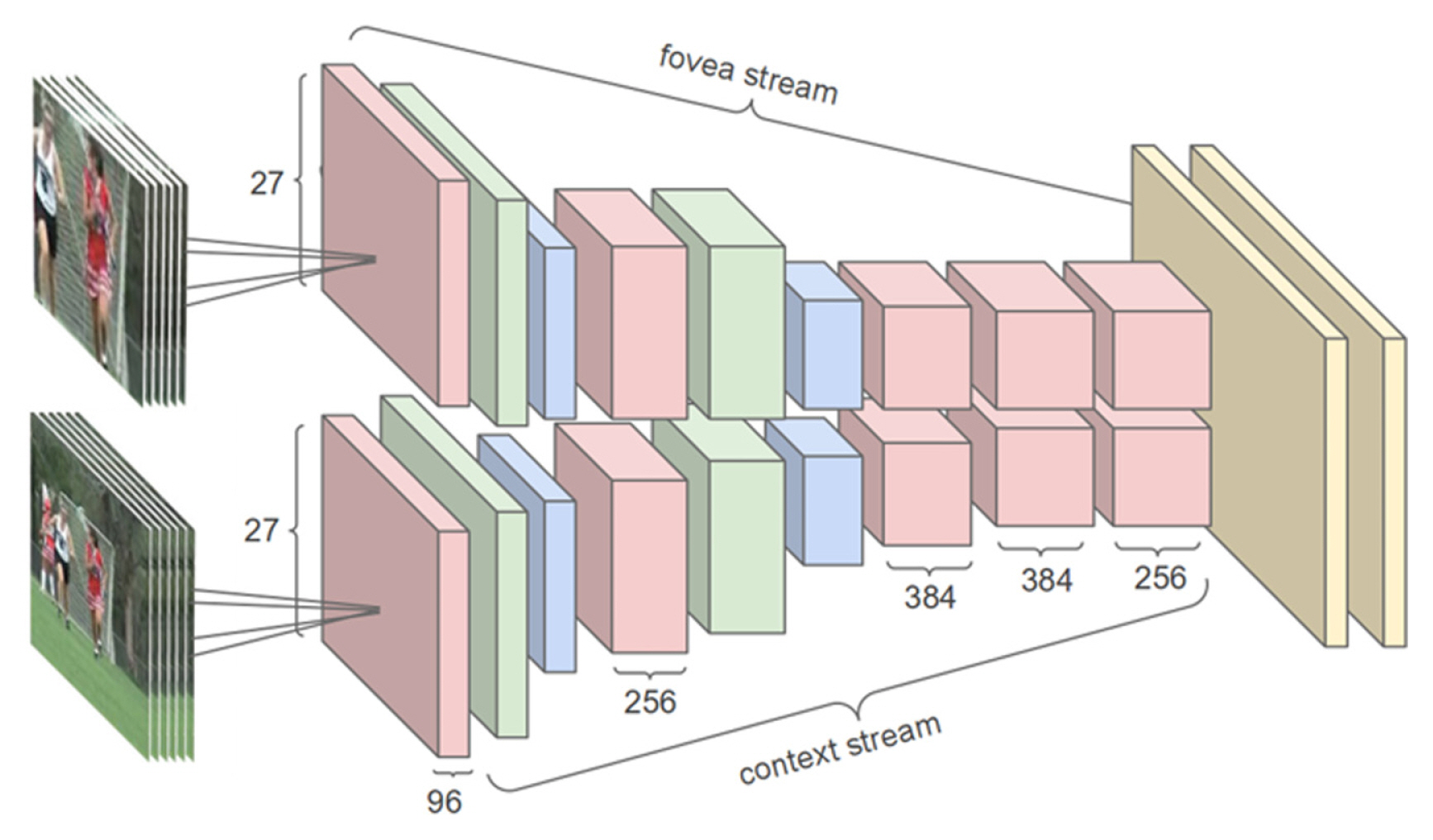
Fig.┬Ā12
2D and 3D convolution operations [ 58] (Adapted from Ref. 58 on the basis of OA) 
Fig.┬Ā13
Data creation for assembly monitoring as discussed in [ 67] (Adapted from Ref. 67 on the basis of OA) 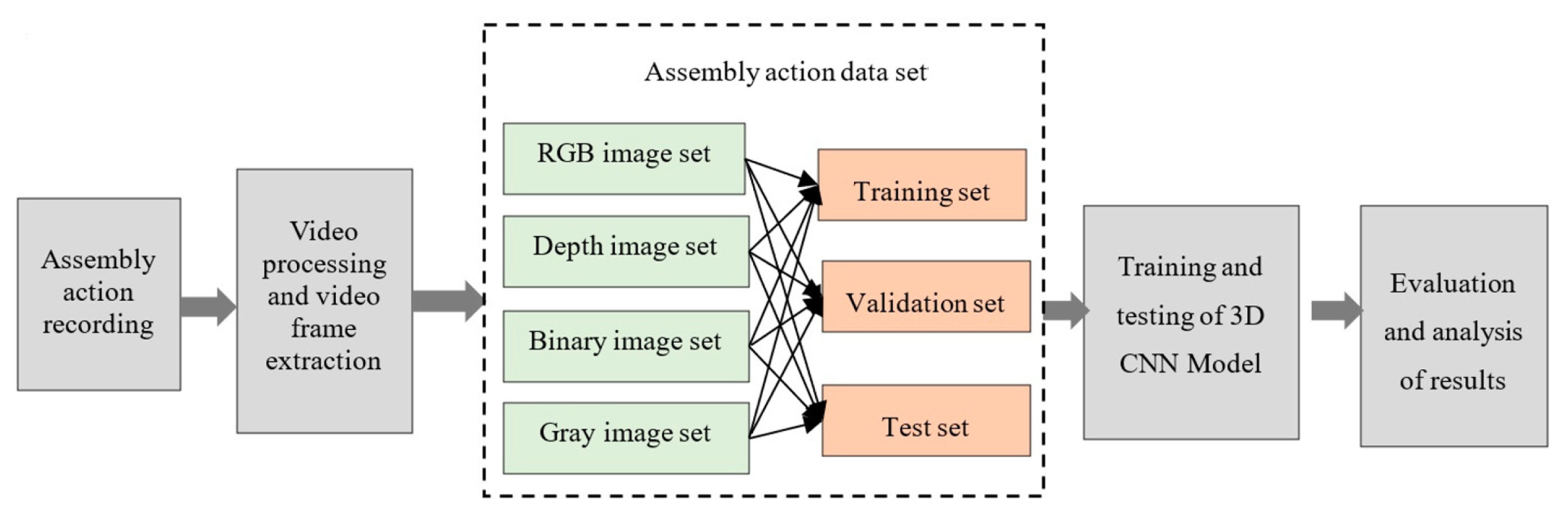
Fig.┬Ā14
Flowchart of the monitoring process [ 69] (Adapted from Ref. 69 with permission) 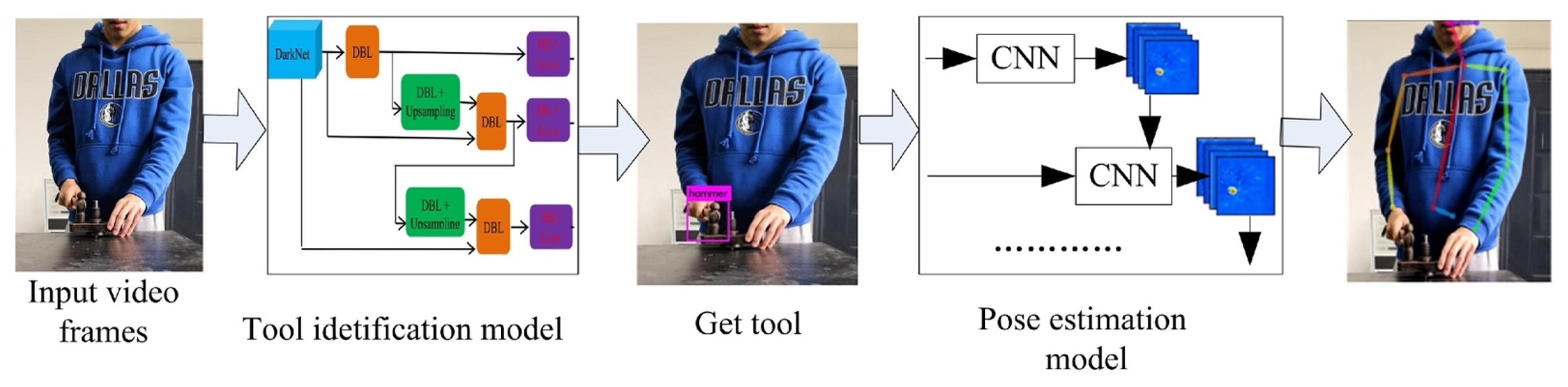
Fig.┬Ā15
Flowchart of two-stream model training and transfer learning for manufacturing scenarios [ 77] (Adapted from Ref. 77 with permission) 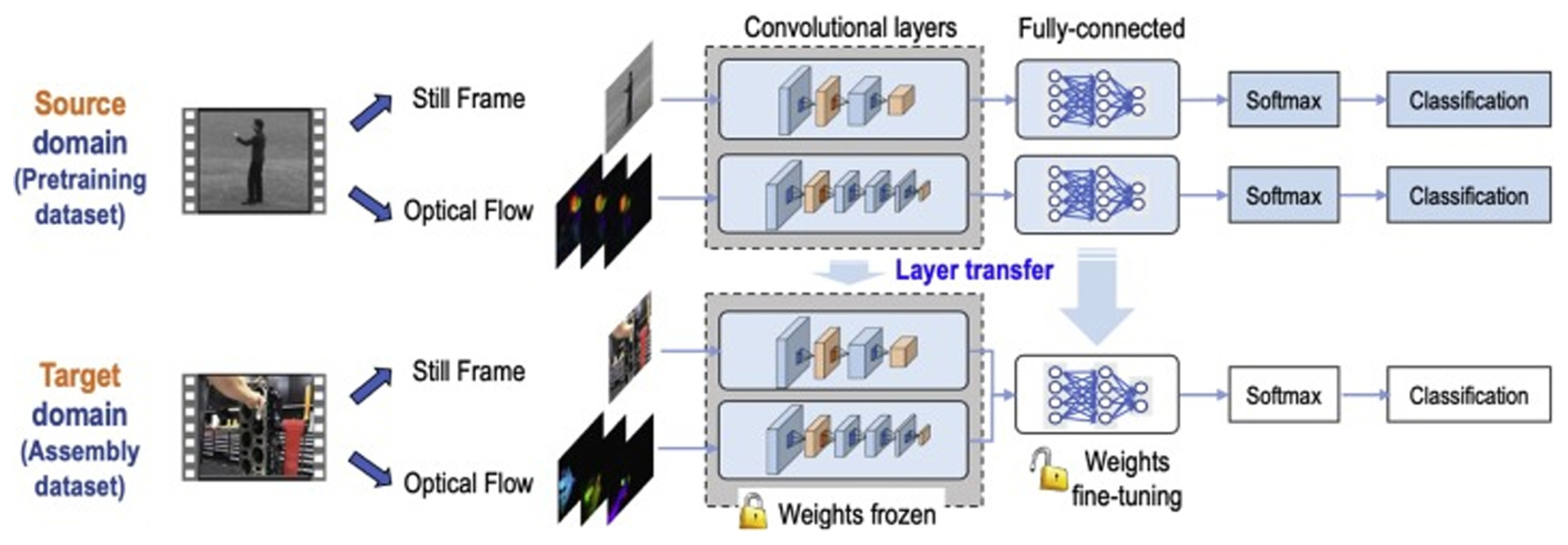
Fig.┬Ā16
Distribution of energy scores for SOP steps and NVA activities [ 12] (Adapted from Ref. 12 with permission) 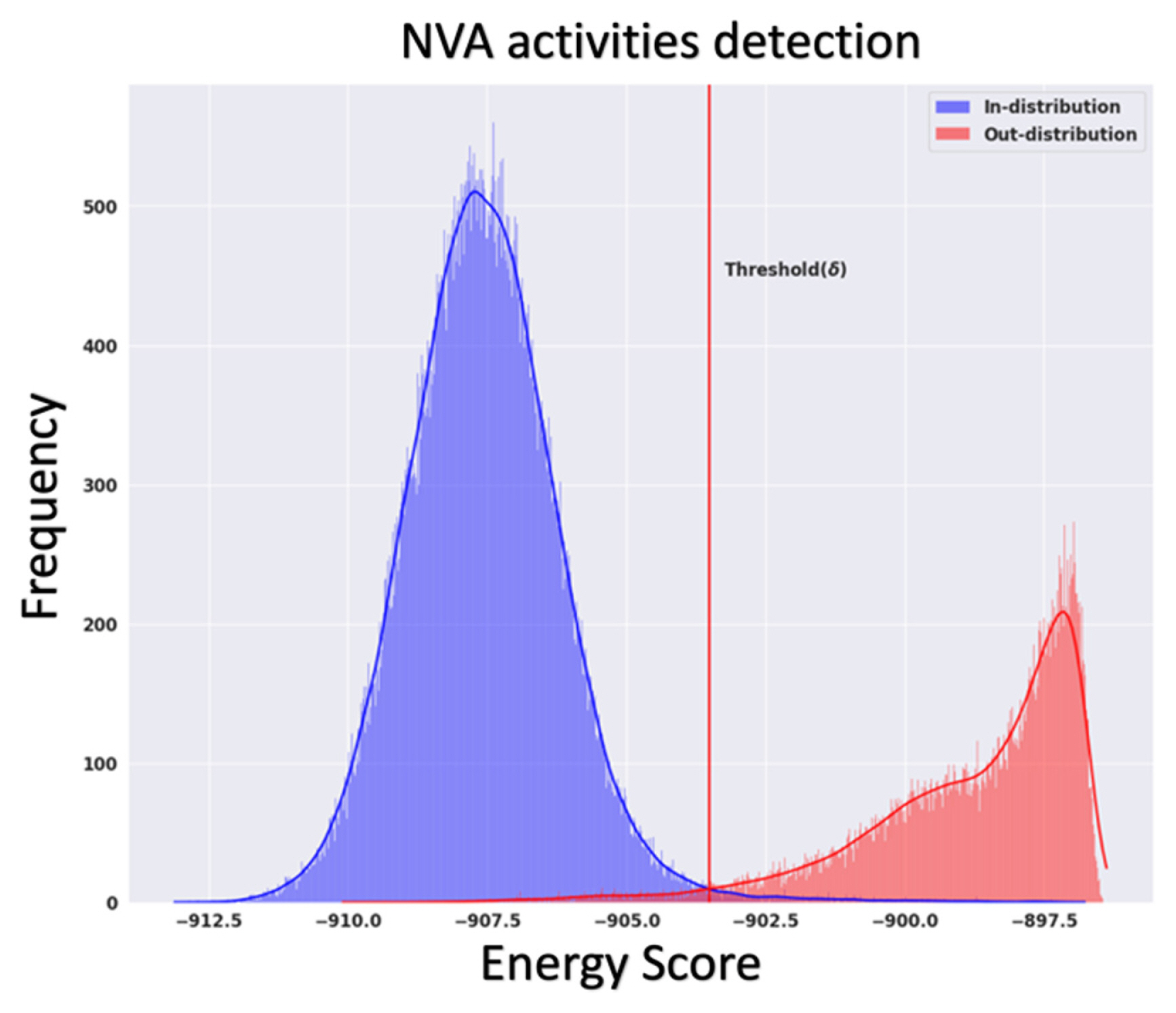
Fig.┬Ā17
An assembly guidance system that can detect tools and components and provide audio-visual cues on anomalies [ 12] (Adapted from Ref. 12 with permission) 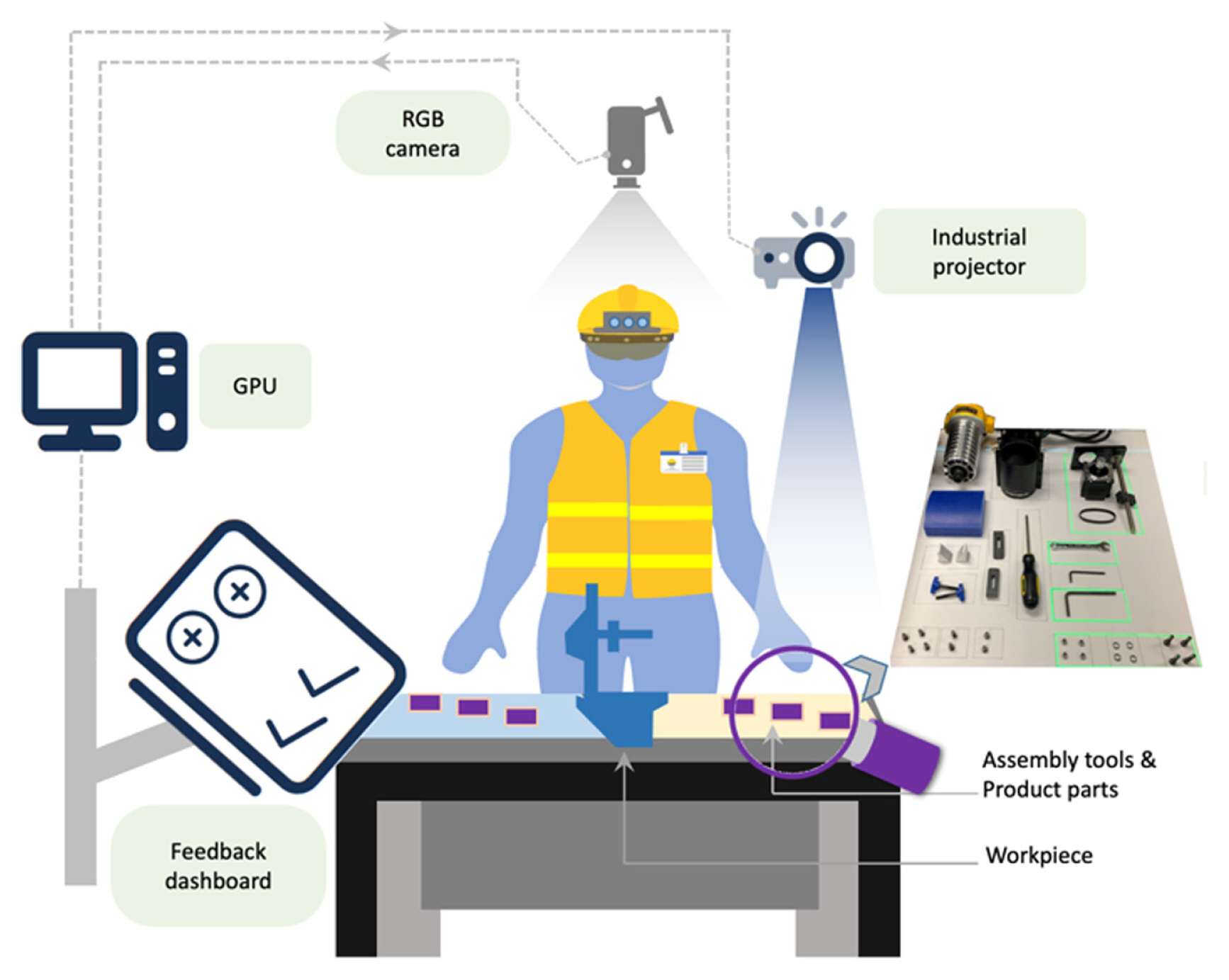
Fig.┬Ā18
Assembly 101 dataset [ 99] (Adapted from Ref. 99 on the basis of OA): Both static and egocentric viewpoints with fine-grained and coarse-grained annotated 
Fig.┬Ā19
Human-centric assembly in future factories [ 80] (Adapted from Ref. 80 on the basis of OA) 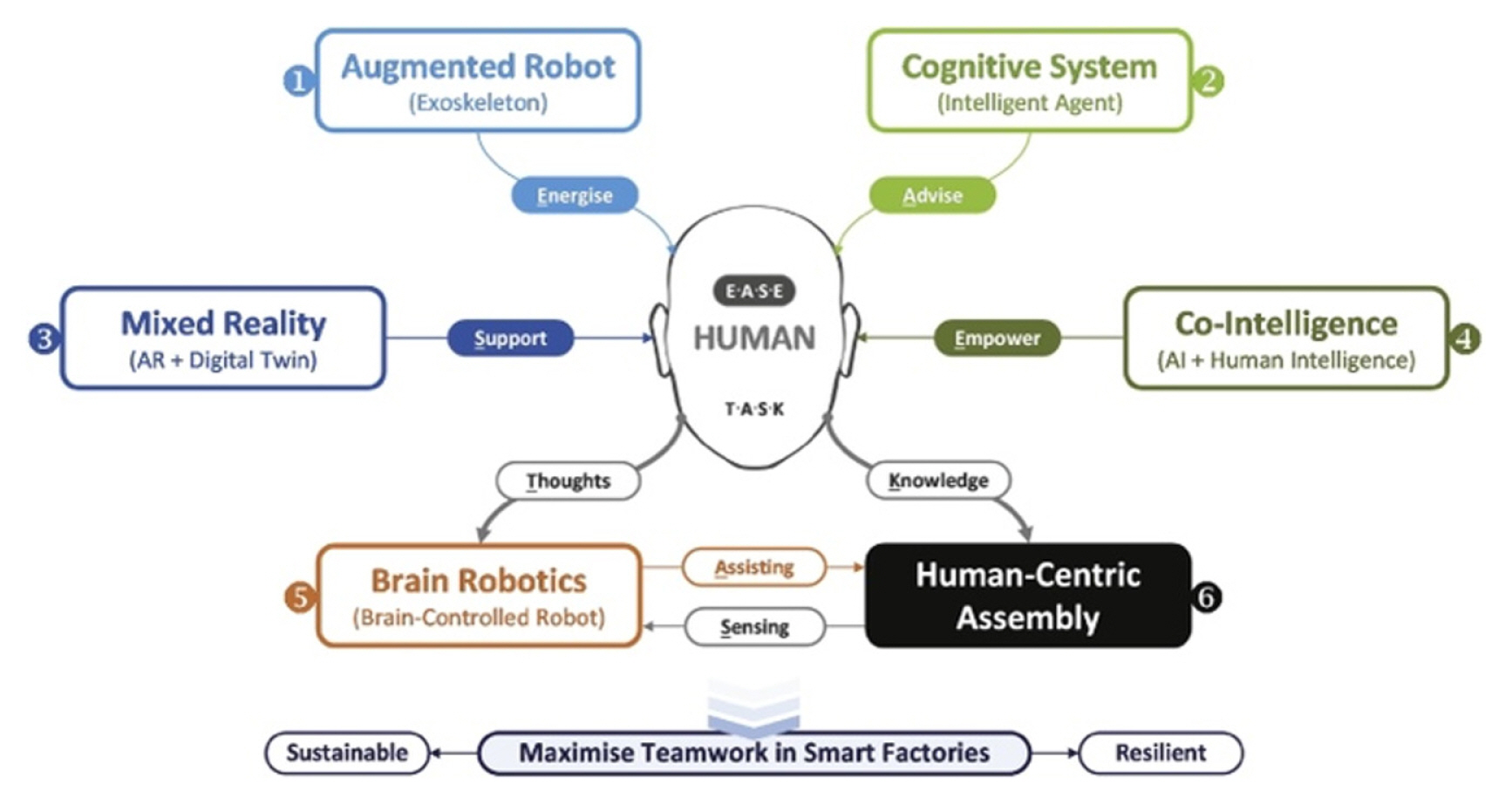
References
1. Kang, H.S., Lee, J.Y., Choi, S., Kim, H., Park, J.H., Son, J.Y., Kim, B.H. & Noh, S.D. (2016). Smart manufacturing: Past research, present findings, and future directions. International Journal of Precision Engineering and Manufacturing-Green Technology, 3, 111ŌĆō128.   2. Liang, Y., Lu, X., Li, W. & Wang, S. (2018). Cyber physical system and big data enabled energy efficient machining optimisation. Journal of Cleaner Production, 187, 46ŌĆō62. 3. Lim, K.Y.H., Zheng, P. & Chen, C.-H. (2020). A state-of-the-art survey of digital twin: Techniques, engineering product lifecycle management and business innovation perspectives. Journal of Intelligent Manufacturing, 31, 1313ŌĆō1337. 4. Wang, J., Ye, L., Gao, R.X., Li, C. & Zhang, L. (2019). Digital twin for rotating machinery fault diagnosis in smart manufacturing. International Journal of Production Research, 57(12), 3920ŌĆō3934. 5. Gao, R.X., Wang, L., Helu, M. & Teti, R. (2020). Big data analytics for smart factories of the future. CIRP Annals, 69(2), 668ŌĆō692. 6. Wang, B., Zheng, P., Yin, Y., Shih, A. & Wang, L. (2022). Toward human-centric smart manufacturing: A human-cyber-physical systems (HCPS) perspective. Journal of Manufacturing Systems, 63, 471ŌĆō490. 7. Aehnelt, M., Gutzeit, E. & Urban, B. (2014). Using activity recognition for the tracking of assembly processes: Challenges and requirements. WOAR, 2014, 12ŌĆō21.
8. Marcus, G., (2018). Deep learning: A critical appraisal. arXiv preprint arXiv:1801.00631.
9. Heilbron, F.C., Escorcia, V.Ghanem, B. & Niebles, J.C. (2015). Activitynet: A large-scale video benchmark for human activity understanding. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR); pp 961ŌĆō970. 10. Kay, W., Carreira, J., Simonyan, K., Zhang, B., Hillier, C., Vijayanarasimhan, S., Viola, F., Green, T., Back, T. & Natsev, P. (2017). The Kinetics Human Action Video Dataset. arXiv preprint arXiv:1705.06950.
11. Stiefmeier, T., Ogris, G.Junker, H.Lukowicz, P. & Troster, G. (2006). Combining motion sensors and ultrasonic hands tracking for continuous activity recognition in a maintenance scenario. In: Proceedings of the 2006 10th IEEE International Symposium on Wearable Computers; pp 97ŌĆō104. 12. Selvaraj, V., Al-Amin, M., Tao, W. & Min, S. (2023). Intelligent assembly operations monitoring with the ability to detect non-value-added activities as out-of-distribution (OOD) instances. CIRP Annals
https://doi.org/10.1016/j.cirp.2023.04.027. 13. Attal, F., Mohammed, S., Dedabrishvili, M., Chamroukhi, F., Oukhellou, L. & Amirat, Y. (2015). Physical human activity recognition using wearable sensors. Sensors, 15(12), 31314ŌĆō31338. 14. Bussmann, J., Martens, W., Tulen, J., Schasfoort, F., Van Den Berg-Emons, H. & Stam, H. (2001). Measuring daily behavior using ambulatory accelerometry: The Activity Monitor. Behavior Research Methods, Instruments, & Computers, 33, 349ŌĆō356.  15. Lee, S.-W., & Mase, K. (2002). , Activity and location recognition using wearable sensors. IEEE Pervasive Computing, 1(3), 24ŌĆō32. 16. Van Laerhoven, K., & Cakmakci, O. (2000). What shall we teach our pants. In: Proceedings of the Digest of Papers. Fourth International Symposium on Wearable Computers; pp 77ŌĆō83. 17. Bao, L., & Intille, S.S. (2004). Activity recognition from user-annotated acceleration data. In: Proceedings of the Pervasive Computing: Second International Conference; pp 1ŌĆō17. 18. Korpela, J., Takase, K.Hirashima, T.Maekawa, T.Eberle, J.Chakraborty, D. & Aberer, K. (2015). An energy-aware method for the joint recognition of activities and gestures using wearable sensors. In: Proceedings of the 2015 ACM International Symposium on Wearable Computers; pp 101ŌĆō108. 19. Maekawa, T., & Watanabe, S. (2011). Unsupervised activity recognition with userŌĆÖs physical characteristics data. In: Proceedings of the 2011 15th Annual International Symposium on Wearable Computers; pp 89ŌĆō96. 20. Ranjan, J., & Whitehouse, K. (2015). Object hallmarks: Identifying object users using wearable wrist sensors. In: Proceedings of the 2015 ACM International Joint Conference on Pervasive and Ubiquitous Computing; pp 51ŌĆō61.
21. Thomaz, E., Essa, I. & Abowd, G.D. (2015). A practical approach for recognizing eating moments with wrist-mounted inertial sensing. In: Proceedings of the 2015 ACM International Joint Conference on Pervasive and Ubiquitous Computing; pp 1029ŌĆō1040. 22. Maekawa, T., Kishino, Y., Sakurai, Y. & Suyama, T. (2013). Activity recognition with hand-worn magnetic sensors. Personal and Ubiquitous Computing, 17, 1085ŌĆō1094. 23. Maekawa, T., Nakai, D.Ohara, K. & Namioka, Y. (2016). Toward practical factory activity recognition: Unsupervised understanding of repetitive assembly work in a factory. In: Proceedings of the 2016 ACM International Joint Conference on Pervasive and Ubiquitous Computing; pp 1088ŌĆō1099.
24. Namioka, Y., Nakai, D., Ohara, K. & Maekawa, T. (2017). Automatic measurement of lead time of repetitive assembly work in a factory using a wearable sensor. Journal of Information Processing, 25, 901ŌĆō911. 25. Qingxin, X., Wada, A.Korpela, J.Maekawa, T. & Namioka, Y. (2019). Unsupervised factory activity recognition with wearable sensors using process instruction information. In: Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies; 3(2)pp 1ŌĆō23. 26. Xia, Q., Korpela, J.Namioka, Y. & Maekawa, T. (2020). Robust unsupervised factory activity recognition with body-worn accelerometer using temporal structure of multiple sensor data motifs. In: Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies; 4(3)pp 1ŌĆō30. 27. Cleland, I., Kikhia, B., Nugent, C., Boytsov, A., Hallberg, J., Synnes, K., McClean, S. & Finlay, D. (2013). Optimal placement of accelerometers for the detection of everyday activities. Sensors, 13(7), 9183ŌĆō9200.  28. Ermes, M., P├żrkk├ż, J., M├żntyj├żrvi, J. & Korhonen, I. (2008). Detection of daily activities and sports with wearable sensors in controlled and uncontrolled conditions. IEEE Transactions on Information Technology in Biomedicine, 12(1), 20ŌĆō26. 29. Guan, D., Ma, T., Yuan, W., Lee, Y.-K. & Jehad Sarkar, A. (2011). Review of sensor-based activity recognition systems. IETE Technical Review, 28(5), 418ŌĆō433. 30. Chen, L., Hoey, J., Nugent, C.D., Cook, D.J. & Yu, Z. (2012). Sensor-based activity recognition. IEEE Transactions on Systems, Man, and Cybernetics, Part C (Applications and Reviews), 42(6), 790ŌĆō808. 31. Lara, O.D., & Labrador, M.A. (2012). A survey on human activity recognition using wearable sensors. IEEE Communications Surveys & Tutorials, 15(3), 1192ŌĆō1209. 32. Gao, L., Bourke, A. & Nelson, J. (2014). Evaluation of accelerometer based multi-sensor versus single-sensor activity recognition systems. Medical Engineering & Physics, 36(6), 779ŌĆō785. 33. Nausch, M., Hold, P. & Sihn, W. (2021). A methodological approach for monitoring assembly processes. In: Procedia CIRP; 104, pp 1233ŌĆō1238. 34. Ogris, G., Lukowicz, P., Stiefmeier, T. & Tr├Čster, G. (2012). Continuous activity recognition in a maintenance scenario: Combining motion sensors and ultrasonic hands tracking. Pattern Analysis and Applications, 15, 87ŌĆō111. 35. Koskimaki, H., Huikari, V.Siirtola, P.Laurinen, P. & Roning, J. (2009). Activity recognition using a wrist-worn inertial measurement unit: A case study for industrial assembly lines. In: Proceedings of the 2009 17th mediterranean conference on control and automation; pp 401ŌĆō405. 36. Koskim├żki, H., Huikari, V., Siirtola, P. & R├Čning, J. (2013). Behavior modeling in industrial assembly lines using a wrist-worn inertial measurement unit. Journal of Ambient Intelligence and Humanized Computing, 4, 187ŌĆō194. 37. Prinz, C., Fahle, S.Kuhlenk├Čtter, B.Losacker, N.Zhang, W. & Cai, W. (2021). Human-centered artificial intelligence application: recognition of manual assembly movements for skill-based enhancements. In: Proceedings of the Conference on Learning Factories (CLF). 38. Lukowicz, P., Ward, J.A.Junker, H.St├żger, M.Tr├Čster, G.Atrash, A. & Starner, T. (2004). Recognizing workshop activity using body worn microphones and accelerometers. In: Proceedings of the Pervasive Computing: Second International Conference; pp 18ŌĆō32. 39. Stiefmeier, T., Roggen, D., Ogris, G., Lukowicz, P. & Tr├Čster, G. (2008). Wearable activity tracking in car manufacturing. IEEE Pervasive Computing, 7(2), 42ŌĆō50. 40. Tao, W., Lai, Z.-H.Leu, M.C. & Yin, Z. (2018). Worker activity recognition in smart manufacturing using IMU and sEMG signals with convolutional neural networks. In: Procedia Manufacturing; 26, pp 1159ŌĆō1166. 41. Tao, W., Chen, H., Moniruzzaman, M., Leu, M.C., Yi, Z. & Qin, R. (2021). Attention-based sensor fusion for human activity recognition using imu signals. arXiv preprint arXiv:2112.11224.
42. Tao, W., Leu, M.C. & Yin, Z. (2020). Multi-modal recognition of worker activity for human-centered intelligent manufacturing. Engineering Applications of Artificial Intelligence, 95, 103868. 43. Poppe, R., (2010). A survey on vision-based human action recognition. Image and Vision Computing, 28(6), 976ŌĆō990. 44. Weinland, D., Ronfard, R. & Boyer, E. (2011). A survey of vision-based methods for action representation, segmentation and recognition. Computer Vision and image Understanding, 115(2), 224ŌĆō241. 45. Ramanathan, M., Yau, W.-Y. & Teoh, E.K. (2014). Human action recognition with video data: Research and evaluation challenges. IEEE Transactions on Human-Machine Systems, 44(5), 650ŌĆō663. 46. Chen, C., Jafari, R. & Kehtarnavaz, N. (2017). A survey of depth and inertial sensor fusion for human action recognition. Multimedia Tools and Applications, 76, 4405ŌĆō4425. 47. Xia, H., & Zhan, Y. (2020). A survey on temporal action localization. IEEE Access, 8, 70477ŌĆō70487. 48. Lowe, D.G., (1999). Object recognition from local scale-invariant features. In: Proceedings of the Seventh IEEE International Conference on Computer Vision; pp 1150ŌĆō1157. 49. Lowe, D.G., (2004). Distinctive image features from scale-invariant keypoints. International Journal of Computer Vision, 60, 91ŌĆō110. 50. Dalal, N., & Triggs, B. (2005). Histograms of oriented gradients for human detection. In: Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPRŌĆÖ05); pp 886ŌĆō893. 51. Krizhevsky, A., Sutskever, I. & Hinton, G.E. (2017). Imagenet classification with deep convolutional neural networks. Communications of the ACM, 60(6), 84ŌĆō90. 52. Carreira, J., & Zisserman, A. (2017). Quo vadis, action recognition? A new model and the kinetics dataset. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; pp 6299ŌĆō6308. 53. Soomro, K., Zamir, A.R. & Shah, M. (2012). UCF101: A dataset of 101 human actions classes from videos in the wildarXiv preprint arXiv:1212.0402.
54. Kuehne, H., Jhuang, H.Garrote, E.Poggio, T. & Serre, T. (2011). HMDB: A large video database for human motion recognition. In: Proceedings of the 2011 International Conference on Computer Vision; pp 2556ŌĆō2563. 55. Ji, S., Xu, W., Yang, M. & Yu, K. (2012). 3D convolutional neural networks for human action recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 35(1), 221ŌĆō231. 56. Karpathy, A., Toderici, G.Shetty, S.Leung, T.Sukthankar, R. & Fei-Fei, L. (2014). Large-scale video classification with convolutional neural networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; pp 1725ŌĆō1732. 57. Simonyan, K., & Zisserman, A. (2014). Two-stream convolutional networks for action recognition in videos. Advances in Neural Information Processing Systems, 27, 1ŌĆō9.
58. Tran, D., Bourdev, L.Fergus, R.Torresani, L. & Paluri, M. (2015). Learning spatiotemporal features with 3d convolutional networks. In: Proceedings of the IEEE International Conference on Computer Vision; pp 4489ŌĆō4497. 59. Wang, L., Xiong, Y.Wang, Z.Qiao, Y.Lin, D.Tang, X. & Van Gool, L. (2016). Temporal segment networks: Towards good practices for deep action recognition. In: Proceedings of the European Conference on Computer Vision; pp 20ŌĆō36. 60. Varol, G., Laptev, I. & Schmid, C. (2017). Long-term temporal convolutions for action recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 40(6), 1510ŌĆō1517. 61. Yue-Hei Ng, J., Hausknecht, M.Vijayanarasimhan, S.Vinyals, O.Monga, R. & Toderici, G. (2015). Beyond short snippets: Deep networks for video classification. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; pp 4694ŌĆō4702. 62. Donahue, J., Anne Hendricks, L.Guadarrama, S.Rohrbach, M.Venugopalan, S.Saenko, K. & Darrell, T. (2015). Long-term recurrent convolutional networks for visual recognition and description. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; pp 2625ŌĆō2634. 63. Baccouche, M., Mamalet, F., Wolf, C., Garcia, C. & Baskurt, A. (2010). Action classification in soccer videos with long short-term memory recurrent neural networks. ICANN, (2), 154ŌĆō159. 64. Baccouche, M., Mamalet, F.Wolf, C.Garcia, C. & Baskurt, A. (2011). Sequential deep learning for human action recognition. In: Proceedings of the Human Behavior Understanding: Second International Workshop; pp 29ŌĆō39. 65. Yao, L., Torabi, A.Cho, K.Ballas, N.Pal, C.Larochelle, H. & Courville, A. (2015). Describing videos by exploiting temporal structure. In: Proceedings of the IEEE International Conference on Computer Vision; pp 4507ŌĆō4515. 66. Nunez, J.C., Cabido, R., Pantrigo, J.J., Montemayor, A.S. & Velez, J.F. (2018). Convolutional neural networks and long short-term memory for skeleton-based human activity and hand gesture recognition. Pattern Recognition, 76, 80ŌĆō94. 67. Chen, C., Zhang, C., Wang, T., Li, D., Guo, Y., Zhao, Z. & Hong, J. (2020). Monitoring of assembly process using deep learning technology. Sensors, 20(15), 4208. 68. Urgo, M., Tarabini, M. & Tolio, T. (2019). A human modelling and monitoring approach to support the execution of manufacturing operations. CIRP Annals, 68(1), 5ŌĆō8. 69. Chen, C., Wang, T., Li, D. & Hong, J. (2020). Repetitive assembly action recognition based on object detection and pose estimation. Journal of Manufacturing Systems, 55, 325ŌĆō333. 70. Redmon, J., & Farhadi, A. (2018). Yolov3: An incremental improvementarXiv preprint arXiv:1804.02767.
71. Wei, S.-E., Ramakrishna, V.Kanade, T. & Sheikh, Y. (2016). Convolutional pose machines. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; pp 4724ŌĆō4732. 72. Lou, P., Li, J., Zeng, Y., Chen, B. & Zhang, X. (2022). Real-time monitoring for manual operations with machine vision in smart manufacturing. Journal of Manufacturing Systems, 65, 709ŌĆō719. 73. Bochkovskiy, A., Wang, C.-Y. & Liao, H-YM (2020). Yolov4: Optimal speed and accuracy of object detection. arXiv preprint arXiv:2004.10934.
74. Yan, J., & Wang, Z. (2022). YOLO V3+ VGG16-based automatic operations monitoring and analysis in a manufacturing workshop under Industry 4.0. Journal of Manufacturing Systems, 63, 134ŌĆō142. 75. Simonyan, K., & Zisserman, A. (2014). Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556.
76. Chen, C., Zhang, C., Li, C. & Hong, J. (2022). Assembly monitoring using semantic segmentation network based on multiscale feature maps and trainable guided filter. IEEE Transactions on Instrumentation and Measurement, 71, 1ŌĆō11. 77. Xiong, Q., Zhang, J., Wang, P., Liu, D. & Gao, R.X. (2020). Transferable two-stream convolutional neural network for human action recognition. Journal of Manufacturing Systems, 56, 605ŌĆō614. 78. Zhang, J., Wang, P. & Gao, R.X. (2021). Hybrid machine learning for human action recognition and prediction in assembly. Robotics and Computer-Integrated Manufacturing, 72, 102184. 79. Wang, L., Gao, R., V├Īncza, J., Kr├╝ger, J., Wang, X.V., Makris, S. & Chryssolouris, G. (2019). Symbiotic human-robot collaborative assembly. CIRP Annals, 68(2), 701ŌĆō726. 80. Wang, L., (2022). A futuristic perspective on human-centric assembly. Journal of Manufacturing Systems, 62, 199ŌĆō201. 81. Kr├╝ger, J., Lien, T.K. & Verl, A. (2009). Cooperation of human and machines in assembly lines. CIRP Annals, 58(2), 628ŌĆō646. 82. Michalos, G., Makris, S., Papakostas, N., Mourtzis, D. & Chryssolouris, G. (2010). Automotive assembly technologies review: Challenges and outlook for a flexible and adaptive approach. CIRP Journal of Manufacturing Science and Technology, 2(2), 81ŌĆō91. 83. Hendrycks, D., & Gimpel, K. (2016). A baseline for detecting misclassified and out-of-distribution examples in neural networks. arXiv preprint arXiv:1610.02136.
84. Liang, S., Li, Y. & Srikant, R. (2017). Enhancing the reliability of out-of-distribution image detection in neural networks. arXiv preprint arXiv:1706.02690.
85. Hinton, G., Vinyals, O. & Dean, J. (2015). Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531.
86. Pereyra, G., Tucker, G., Chorowski, J., Kaiser, Ł & Hinton, G. (2017). Regularizing neural networks by penalizing confident output distributions. arXiv preprint arXiv:1701.06548.
87. Liu, W., Wang, X., Owens, J. & Li, Y. (2020). Energy-based out-of-distribution detection. Advances in Neural Information Processing Systems, 33, 21464ŌĆō21475.
88. Cui, P., & Wang, J. (2022). Out-of-distribution (OOD) detection based on deep learning: A review. Electronics, 11(21), 3500. 89. Ferri, C., Hern├Īndez-Orallo, J. & Modroiu, R. (2009). An experimental comparison of performance measures for classification. Pattern recognition letters, 30(1), 27ŌĆō38. 90. Fern├Īndez, A.Garc├Ła, S.Galar, M.Prati, R.C.Krawczyk, B. & Herrera, F. (2018). Learning from imbalanced data sets, Springer.
91. Zappi, P., Roggen, D., Farella, E., Tr├Čster, G. & Benini, L. (2012). Network-level power-performance trade-off in wearable activity recognition: A dynamic sensor selection approach. ACM Transactions on Embedded Computing Systems (TECS), 11(3), 1ŌĆō30.
92. Reiss, A., & Stricker, D. (2012). Introducing a new benchmarked dataset for activity monitoring. In: Proceedings of the 2012 16th International Symposium on Wearable Computers; pp 108ŌĆō109. 93. Barshan, B., & Y├╝ksek, M.C. (2014). Recognizing daily and sports activities in two open source machine learning environments using body-worn sensor units. The Computer Journal, 57(11), 1649ŌĆō1667. 94. Shoaib, M., Bosch, S., Incel, O.D., Scholten, H. & Havinga, P.J. (2014). Fusion of smartphone motion sensors for physical activity recognition. Sensors, 14(6), 10146ŌĆō10176. 95. Roggen, D., Calatroni, A.Rossi, M.Holleczek, T.F├Črster, K.Tr├Čster, G.Lukowicz, P.Bannach, D.Pirkl, G. & Ferscha, A. (2010). Collecting complex activity datasets in highly rich networked sensor environments. In: Proceedings of the 2010 Seventh International Conference on Networked Sensing Systems (INSS); pp 233ŌĆō240. 96. Ciliberto, M., Fortes Rey, V., Calatroni, A., Lukowicz, P. & Roggen, D. (2021). Opportunity++: A multimodal dataset for video-and wearable, object and ambient sensors-based human activity recognition. Frontiers in Computer Science, 3,
https://doi.org/10.3389/fcomp.2021.792065. 97. Reddy, K.K., & Shah, M. (2013). Recognizing 50 human action categories of web videos. Machine Vision and Applications, 24(5), 971ŌĆō981. 98. Hara, K., Kataoka, H. & Satoh, Y. (2018). Can spatiotemporal 3D cnns retrace the history of 2D cnns and imagenet? In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; pp 6546ŌĆō6555. 99. Sener, F., Chatterjee, D.Shelepov, D.He, K.Singhania, D.Wang, R. & Yao, A. (2022). Assembly101: A large-scale multi-view video dataset for understanding procedural activities. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition; pp 21096ŌĆō21106. 100. Ragusa, F., Furnari, A.Livatino, S. & Farinella, G.M. (2021). The meccano dataset: Understanding human-object interactions from egocentric videos in an industrial-like domain. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision; pp 1569ŌĆō1578. 101. Ben-Shabat, Y., Yu, X.Saleh, F.Campbell, D.Rodriguez-Opazo, C.Li, H. & Gould, S. (2021). The ikea asm dataset: Understanding people assembling furniture through actions, objects and pose. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision; pp 847ŌĆō859. 102. Alayrac, J.-B., Bojanowski, P.Agrawal, N.Sivic, J.Laptev, I. & Lacoste-Julien, S. (2016). Unsupervised learning from narrated instruction videos. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; pp 4575ŌĆō4583. 103. Zhou, L., Xu, C. & Corso, J. (2018). Towards automatic learning of procedures from web instructional videos. In: Proceedings of the AAAI Conference on Artificial Intelligence;
https://doi.org/10.1609/aaai.v32i1.12342. 104. Zhukov, D., Alayrac, J.-B.Cinbis, R.G.Fouhey, D.Laptev, I. & Sivic, J. (2019). Cross-task weakly supervised learning from instructional videos. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition; pp 3537ŌĆō3545. 105. Tang, Y., Ding, D.Rao, Y.Zheng, Y.Zhang, D.Zhao, L.Lu, J. & Zhou, J. (2019). Coin: A large-scale dataset for comprehensive instructional video analysis. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition; pp 1207ŌĆō1216. 106. Schuldt, C., Laptev, I. & Caputo, B. (2004). Recognizing human actions: a local SVM approach. In: Proceedings of the 17th International Conference on Pattern Recognition; 2004, pp 32ŌĆō36. 107. Gorelick, L., Blank, M., Shechtman, E., Irani, M. & Basri, R. (2007). Actions as space-time shapes. IEEE Transactions on Pattern Analysis and Machine Intelligence, 29(12), 2247ŌĆō2253. 108. Weinland, D., Boyer, E. & Ronfard, R. (2007). Action recognition from arbitrary views using 3D exemplars. In: Proceedings of the 2007 IEEE 11th International Conference on Computer Vision; pp 1ŌĆō7. 109. Xu, X., Lu, Y., Vogel-Heuser, B. & Wang, L. (2021). Industry 4.0 and Industry 5.0ŌĆöInception, conception and perception. Journal of Manufacturing Systems, 61, 530ŌĆō535.
Biography
Vignesh Selvaraj is a graduate student at the University of Wisconsin-Madison pursuing his Ph.D. at the time of this work. He obtained his Master of Science degree from the same University. His research interests are in Smart Manufacturing, and Industrial Internet of Things, particularly focusing on the development of robust and reliable AI models for manufacturing industries.
Biography
Sangkee Min is an Associate Professor at Department of Mechanical Engineering, University of Wisconsin-Madison and a director of Manufacturing Innovation Network Laboratory (MIN Lab: https://min.me.wisc.edu/). He is currently working on three major research topics: UPM (Ultra-Precision Machining), SSM (Smart Sustainable Manufacturing), and MFD (Manufacturing for Design).
|
|
| TOOLS |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
METRICS

|
|
|
|
|
|


 E-mail
E-mail Print
Print facebook
facebook twitter
twitter Linkedin
Linkedin google+
google+


 PDF Links
PDF Links PubReader
PubReader Full text via DOI
Full text via DOI Download Citation
Download Citation  CrossRef TDM
CrossRef TDM


